9 Discrete Probability Distributions
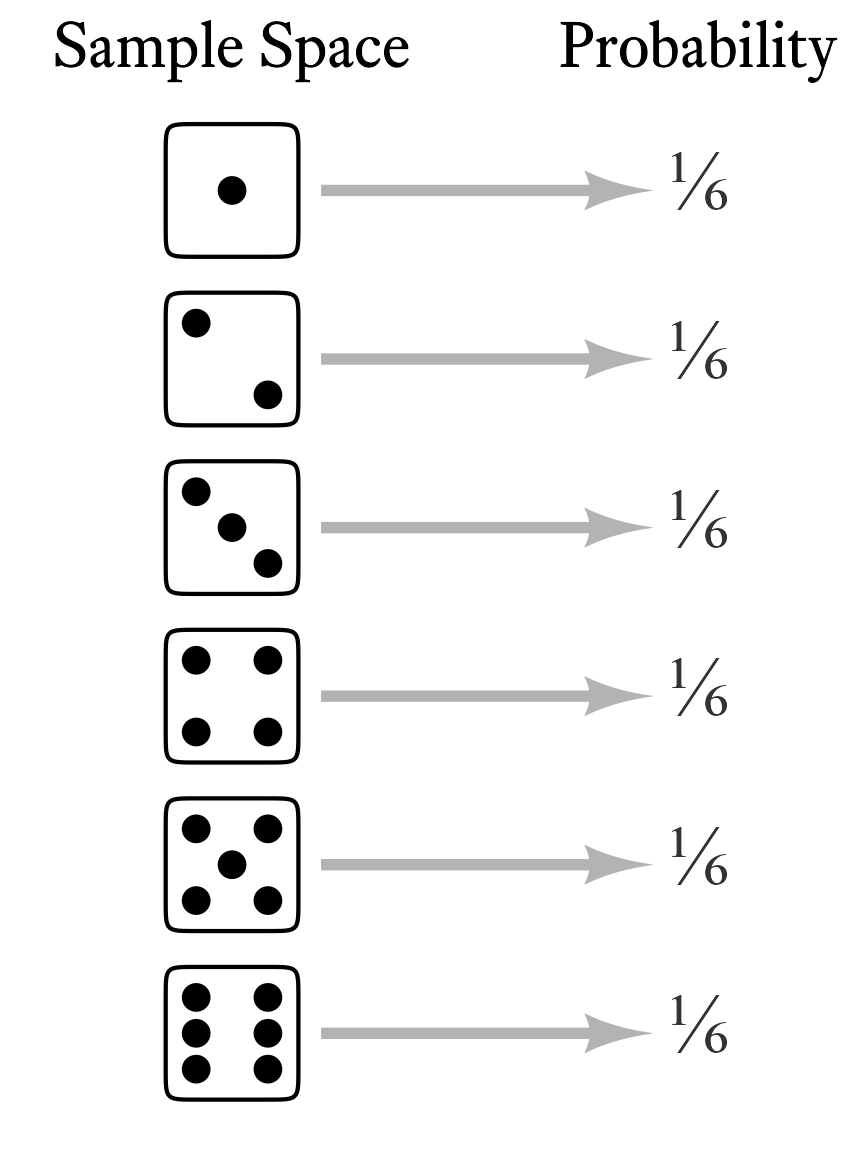
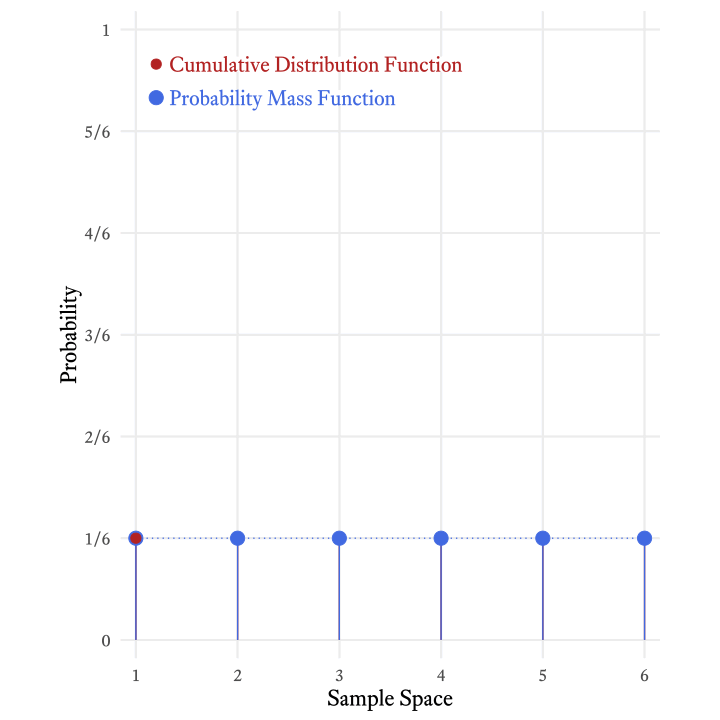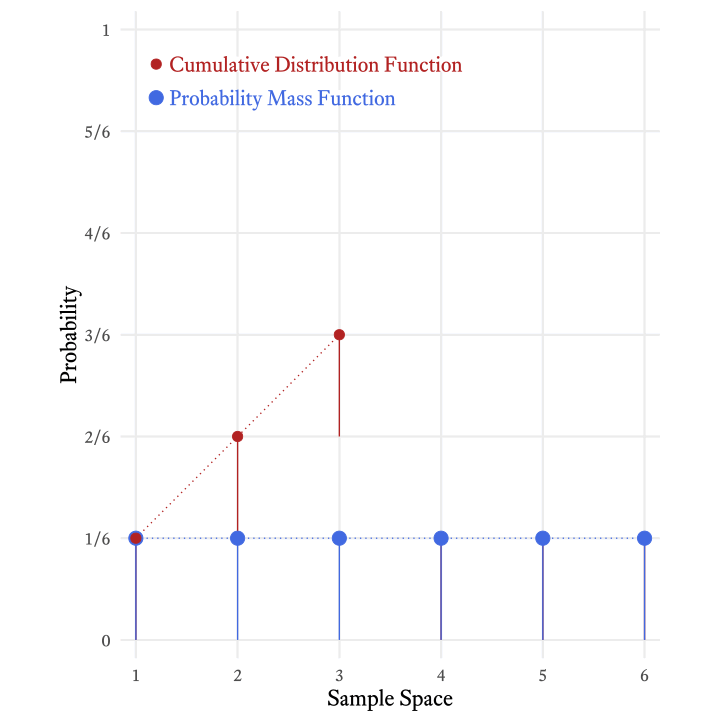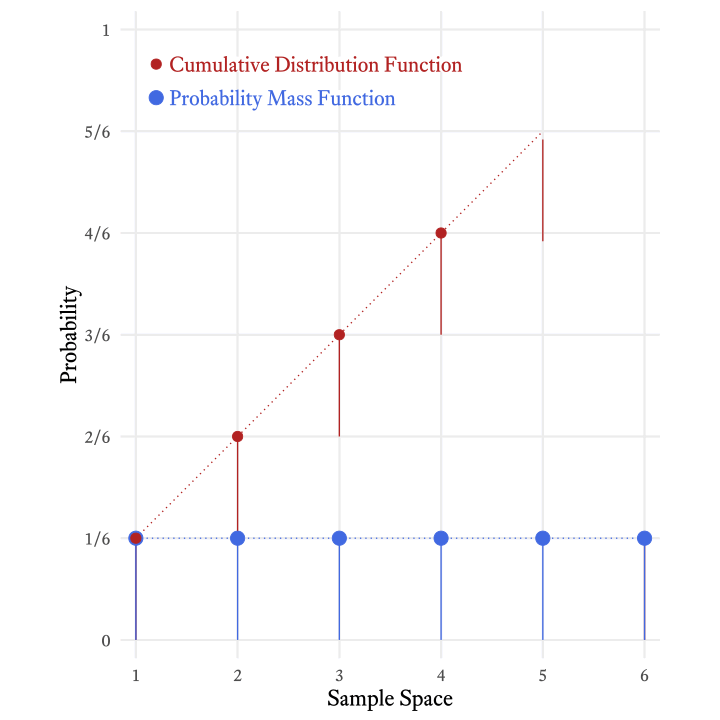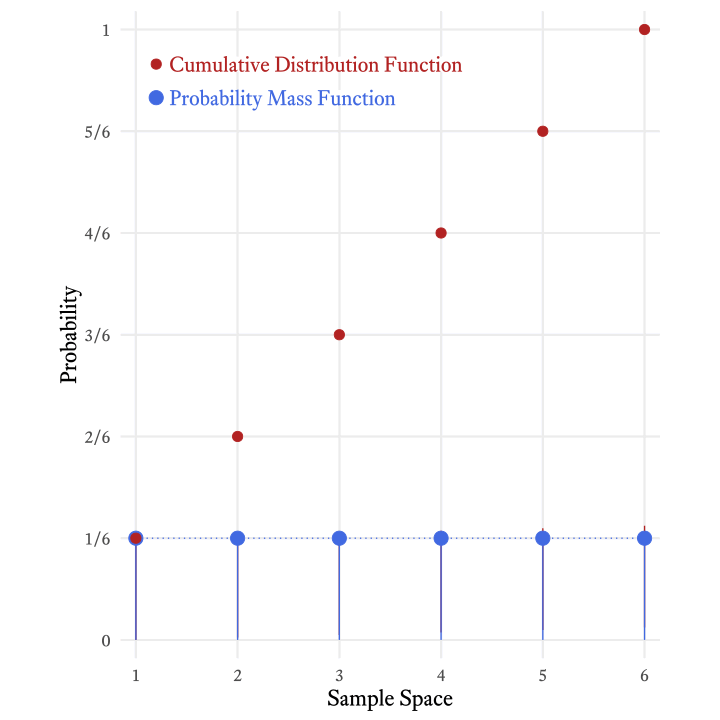
Each element of a random variable’s sample space occurs with a particular probability. When we list the probabilities of each possible outcome, we have specified the variable’s probability distribution. In other words, if we know the probability distribution of a variable, we know how probable each outcome is. In the case of a throw of a single die, each outcome is equally likely (Figure 9.1).
There is an infinite variety of probability distributions, but a small subset of them have been given names. Now, one can manage one’s affairs quite well without ever knowing what a Bernoulli distribution is, or what a \chi{^2} distribution is, or even what a normal distribution is. However, sometimes life is a little easier if we have names for useful things that occur often. Most of the distributions with names are not really single distributions, but families of distributions. The various members of a family are unique but they are united by the fact that their probability distributions are generated by a particular mathematical function (more on that later). In such cases, the probability distribution is often represented by a graph in which the sample space is on the X-axis and the associated probabilities are on the Y-axis. In Figure 9.2, 16 probability distributions that might be interesting and useful to clinicians are illustrated. Keep in mind that what are pictured are only particular members of the families listed; some family members look quite different from what is shown in Figure 9.2.

9.1 Discrete Distrubitions
The sample spaces in discrete distributions are discrete sets. Thus, in the x-axis of the probability distributions, you will see isolated numbers with gaps between each number (e.g., integers).
9.1.1 Discrete Uniform Distributions
The throw of a single die is a member of a family of distributions called the discrete uniform distribution. It is “discrete” because the elements in the sample space are countable, with evenly spaced gaps between them. For example, there might be a sequence of 8, 9, 10, and 11 in the sample space, but there are no numbers in between. It is “uniform” because all outcomes are equally likely. With dice, the numbers range from a lower bound of 1 to an upper bound of 6. In the family of discrete uniform distributions, the lower and upper bounds are typically integers, mostly likely starting with 1. However, any real number a can be the lower bound and the spacing k between numbers can be any positive real number. For the sake of simplicity and convenience, I will assume that the discrete uniform distribution refers to consecutive integers ranging from a lower bound of a and an upper bound of b.
This kind of discrete uniform distribution has a number of characteristics listed in Table 9.1. I will explain each of them in the sections that follow. As we go, I will also explain the mathematical notation. For example, a \in \{\ldots,-1,0,1,\ldots\} means that a is an integer because \in means is a member of and \{\ldots,-1,0,1,\ldots\} is the set of all integers.1 x \in \{a,a+1,\ldots,b\} means that the each member of the sample space x is a member of the set of integers that include a, b, and all the integers between a and b. The notation for the probability mass function and the cumuluative distribution function function will be explained later in this chapter.
1 Notation note: Sometimes the set of all integers is referred to with the symbol \mathbb{Z}.
| Feature | Symbol |
|---|---|
| Lower Bound | a \in \{\ldots,-1,0,1,\ldots\} |
| Upper Bound | b \in \{a + 1, a + 2, \ldots\} |
| Sample Space | x \in\{a, a + 1,\ldots,b\} |
| Number of points | n=b-a+1 |
| Mean | \mu=\frac{a+b}{2} |
| Variance | \sigma^2=\frac{n^2-1}{12} |
| Skewness | \gamma_1=0 |
| Kurtosis | \gamma_2=-\frac{6(n^2+1)}{5(n^2-1)} |
| Probability Mass Function | f_X(x;a,b)=\frac{1}{n} |
| Cumulative Distribution Function | F_X(x;a,b)=\frac{x-a+1}{n} |
9.1.2 Parameters of Random Variables
The lower bound a and the upper bound b are the discrete uniform distribution’s parameters. The word parameter has many meanings, but here it refers to a characteristic of a distribution family that helps us identify precisely which member of the family we are talking about. Most distribution families have one, two, or three parameters.
If you have taken an algebra class, you have seen parameters before, though the word parameter may not have been used. Think about the formula of a line:
y=mx+b
Both x and y are variables, but what are m and b? Well, you probably remember that m is the slope of the line and that b is the y-intercept. If we know the slope and the intercept of a line, we know exactly which line we are talking about. No additional information is needed to graph the line. Therefore, m and b are the line’s parameters, because they uniquely identify the line.2 All lines have a lot in common but there is an infinite variety of lines because the parameters, the slope and the intercept, can take on the value of any real number. Each unique combination of parameter values (slope and intercept) will produce a unique line. So it is with probability distribution families. All family members are alike in many ways, but they also differ because their differing parameters alter the shape of the distributions.
2 What about other mathematical functions? Do they have parameters? Yes! Most do! For example, in the equation for a parabola (y=ax^2+bx+c), a, b, and c determine its precise shape.
3 If we allow the lower bound to be any real number and the spacing to be any positive real number, the discrete uniform distribution can be specified by three parameters: the lower bound a, the spacing between numbers k (k>0), and the number of points n (n>1). The upper bound b of such a distribution would be b=a+k(n-1)
The discrete uniform distribution (i.e., the typical variety consisting of consecutive integers) is defined by the lower and upper bound. Once we know the lower bound and the upper bound, we know exactly which distribution we are talking about.3 Not all distributions are defined by their lower and upper bounds. Indeed, many distribution families are unbounded on one or both sides. Therefore, other features are used to characterize the distributions, such as the population mean (\mu).
9.1.3 Probability Mass Functions
Many distribution families are united by the fact that their probability distributions are generated by a particular mathematical function. For discrete distributions, those functions are called probability mass functions. In general, a mathematical function is an expression that takes one or more constants (i.e., parameters) and one or more input variables, which are then transformed according to some sort of rule to yield a single number.
A probability mass function transforms a random variable’s sample space elements into probabilities. In Figure 9.1, the probability mass function can be thought of as the arrows between the sample space and the probabilities. That is, the probability mass function is the thing that was done to the sample space elements to calculate the probabilities. In Figure 9.1, each outcome of a throw of the the die was mapped onto a probability of ⅙. Why ⅙, and not some other number? The probability mass function of the discrete uniform distribution tells us the answer.
The probability mass function of the discrete uniform distribution is fairly simple but the notation can be intimidating at first (Figure 9.3). By convention, a single random variable is denoted by a capital letter X. Any particular value of X in its sample space is represented by a lowercase x. In other words, X represents the variable in its totality whereas x is merely one value that X can take on. Confusing? Yes, statisticians work very hard to confuse us—and most of the time they succeed!
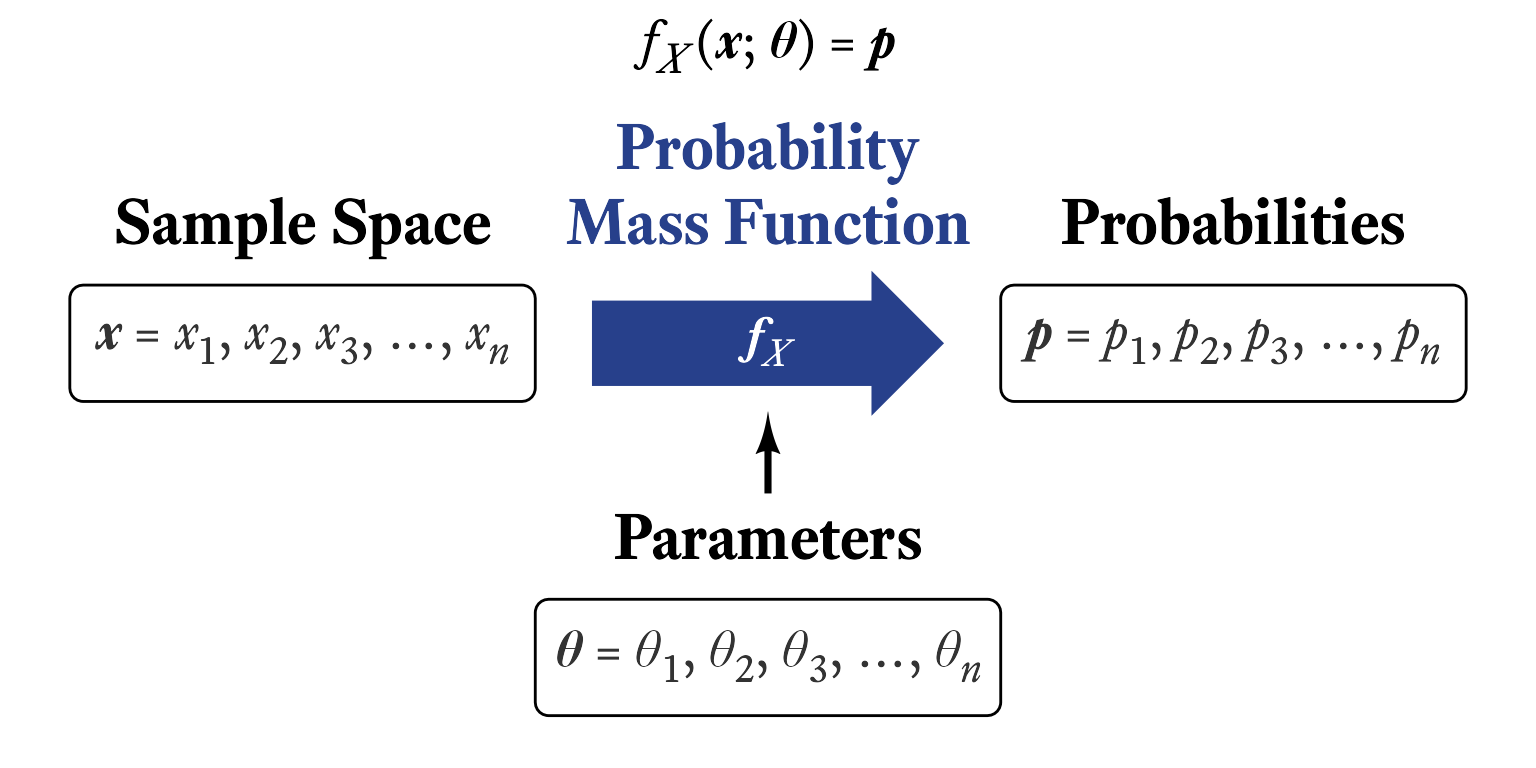
The probability mass function of random variable X is denoted by f_X(x). This looks strange at first. It means, “When random variable X generates a number, what is the probability that the outcome will be a particular value x?” That is, f_X(x)=P(X=x), where P means “What is the probability that…?” Thus, P(X=x) reads, “What is the probability that random variable X will generate a number equal to a particular value x?” So, f_X(7) reads, “When random variable X generates a number, what is the probability that the outcome will be 7?”
Most probability mass functions also have parameters, which are listed after a semi-colon. In the case of the discrete uniform distribution consisting of consecutive integers, the lower and upper bounds a and b are included in the function’s notation like so: f_X(x;a,b). This reads, “For random variable X with parameters a and b, what is the probability that the outcome will be x?” Some parameters can be derived from other parameters, as was the case with the number of points n in the sample space of a discrete uniform distribution: n=b-a+1. The probability for each outcome in the sample space is the same and there are n possible outcomes. Therefore, the probability associated with each outcome is \frac{1}{n}.
Putting all of this together, if a and b are integers and a<b, for all n integers x between a and b, inclusive:
\begin{aligned} f_X\left(x;a,b\right)&=\frac{1}{b-a+1}\\[2ex] &=\frac{1}{n} \end{aligned}
| Symbol | Meaning |
|---|---|
| X | A random variable with a discrete uniform distribution |
| f_X | The probability mass function of X |
| x | Any particular member of the sample space of X |
| a | The lower bound of the sample space |
| b | The upper bound of the sample space |
| n | b-a+1 (The number of points in the sample space) |
You might notice that x is not needed to calculate the probability. Why? Because this is a uniform distribution. No matter which sample space element x we are talking about, the probability associated with it is always the same. In distributions that are not uniform, the position of x matters and thus influences the probability of its occurrence.
9.1.4 Cumulative Distribution Functions
The cumulative distribution function tells us where a sample space element ranks in a distribution. Whereas the probability mass function tells us the probability that a random variable will generate a particular number, the cumulative distribution function tells us the probability that a random variable will generate a particular number or less.
F_X(x) = P(X \le x)=p
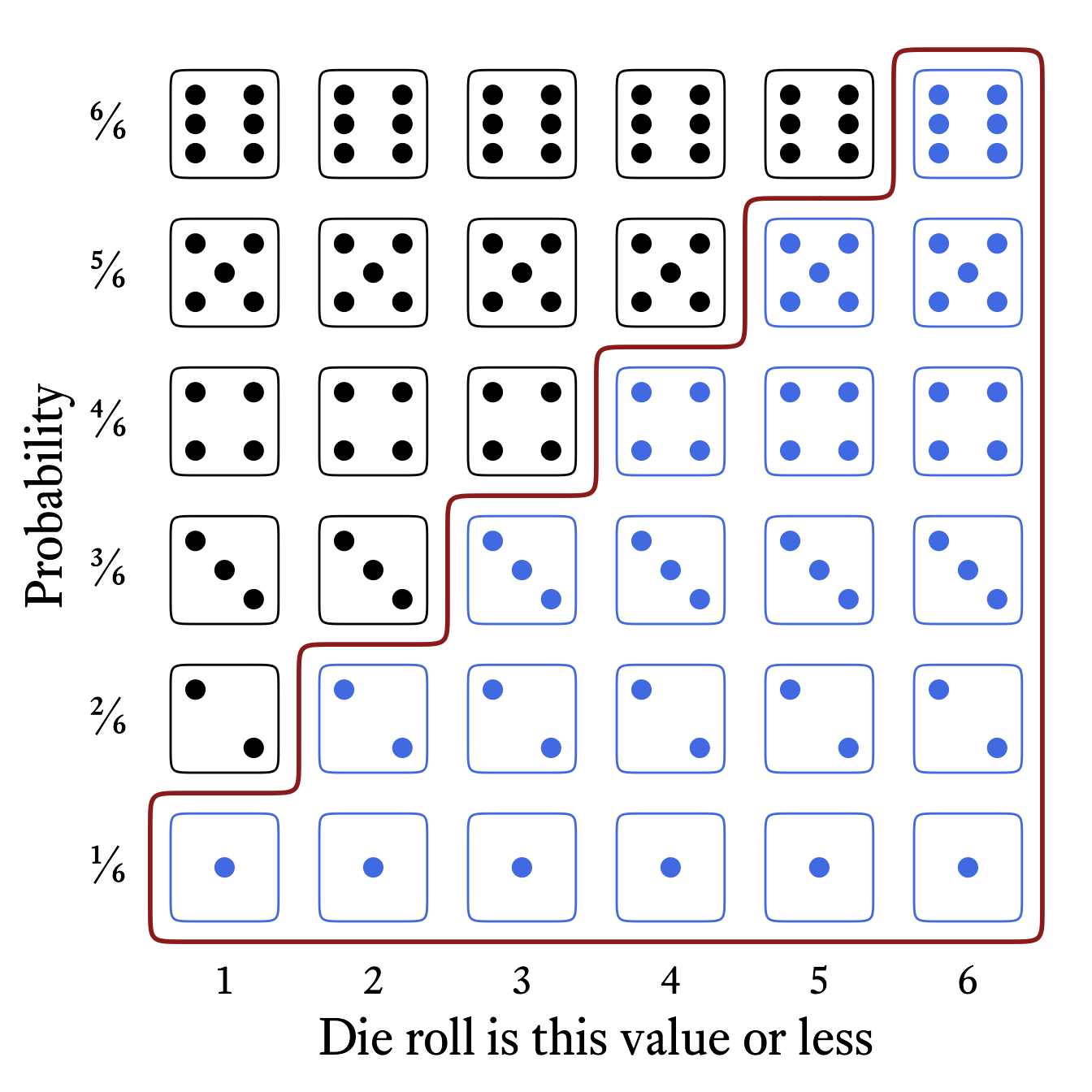
The cumulative distribution function of the roll of a die (Figure 9.4) tells us that the probability of rolling at least a 4 is 4⁄6 (i.e., ⅔).
The cumulative distribution function is often distinguished from the probability mass function with a capital F instead of a lowercase f. In the case of a discrete uniform distribution consisting of n consecutive integers from a to b, the cumulative distribution function is:
\begin{align*} F_X(x;a,b)=\frac{x-a+1}{b-a+1}\\[2ex] =\frac{x-a+1}{n} \end{align*}
| Symbol | Meaning |
|---|---|
| X | A random variable with a discrete uniform distribution |
| F_X | The cumulative distribution function of X |
| x | Any particular member of the sample space of X |
| a | The lower bound of the sample space |
| b | The upper bound of the sample space |
| n | b-a+1 (The number of points in the sample space) |
In the case of the the six-sided die, the cumulative distribution function is
\begin{aligned} F_X(x;a=1,b=6)&=\frac{x-a+1}{b-a+1}\\[2ex] &=\frac{x-1+1}{6-1+1}\\[2ex] &=\frac{x}{6} \end{aligned}
The cumulative distribution function is so-named because it adds all the probabilities in the probability mass function up to and including a particular member of the sample space. Figure 9.5 shows how the each probability in the cumulative distribution function of the roll of a six-sided die is the sum of the current and all previous probabilities in the probability mass function.
9.1.5 Quantile functions
The inverse of the cumulative distribution function is the quantile function. The cumulative distribution starts with a value x in the sample space and tells us p, the proportion of values in that distribution that are less than or equal to x. A quantile function starts with a proportion p and tells us the value x that splits the distribution such that the proportion p of the distribution is less than or equal to x.
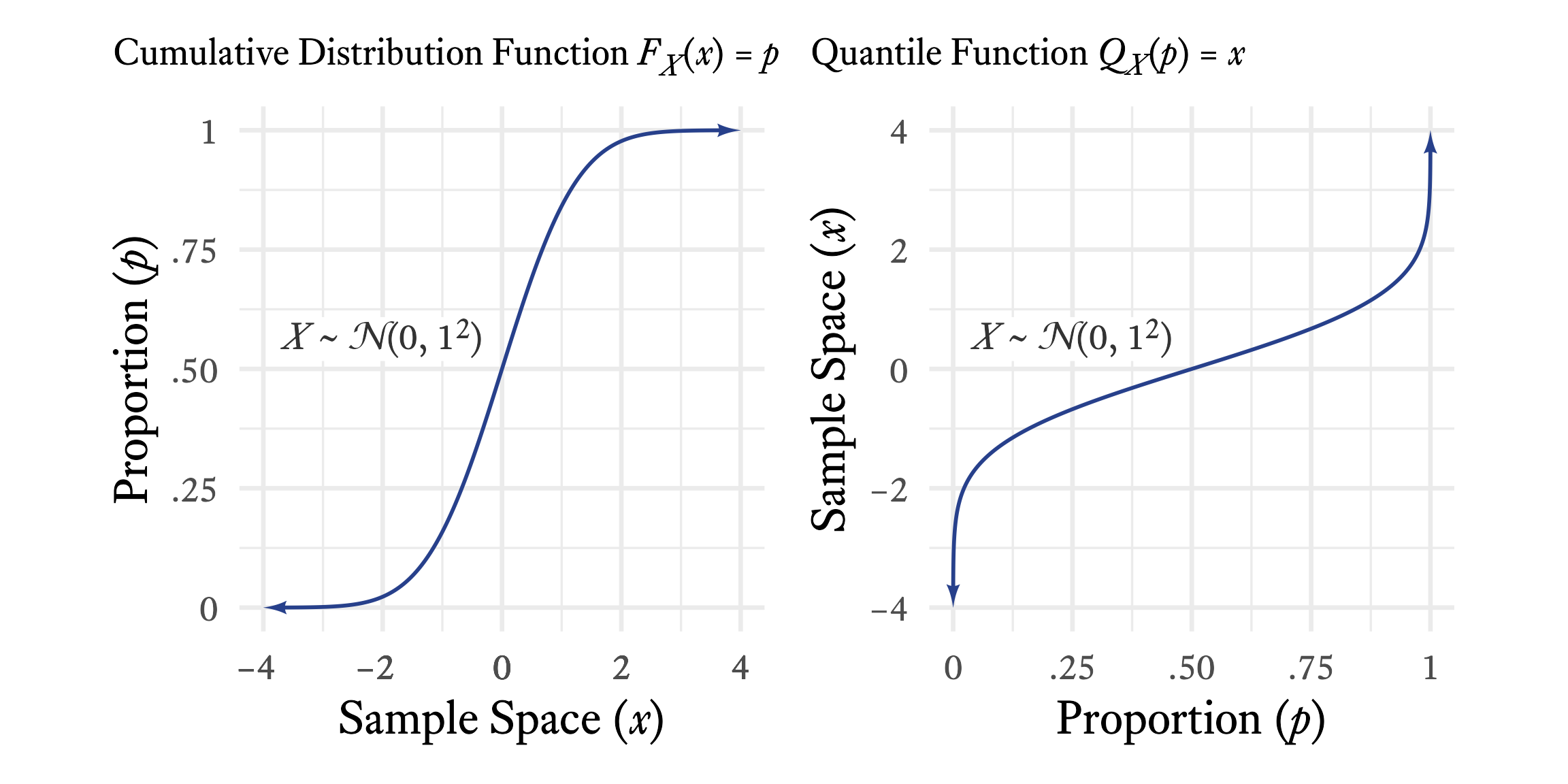
As seen in Figure 9.6, if you see a graph of a continuous distribution function, just flip the X and Y axes, and you have a graph of a quantile function.
9.1.6 Generating a Random Sample in R
In R, the sample function generates numbers from the discrete uniform distribution.
set.seed(1)
# n = the sample size
n <- 6000
# a = the lower bound
a <- 1
# b = the upper bound
b <- 6
# The sample space is the sequence of integers from a to b
sample_space <- seq(a, b)
# X = the sample with a discrete uniform distribution
# The sample function selects n values
# from the sample space with replacement at random
X <- sample(sample_space,
size = n,
replace = TRUE)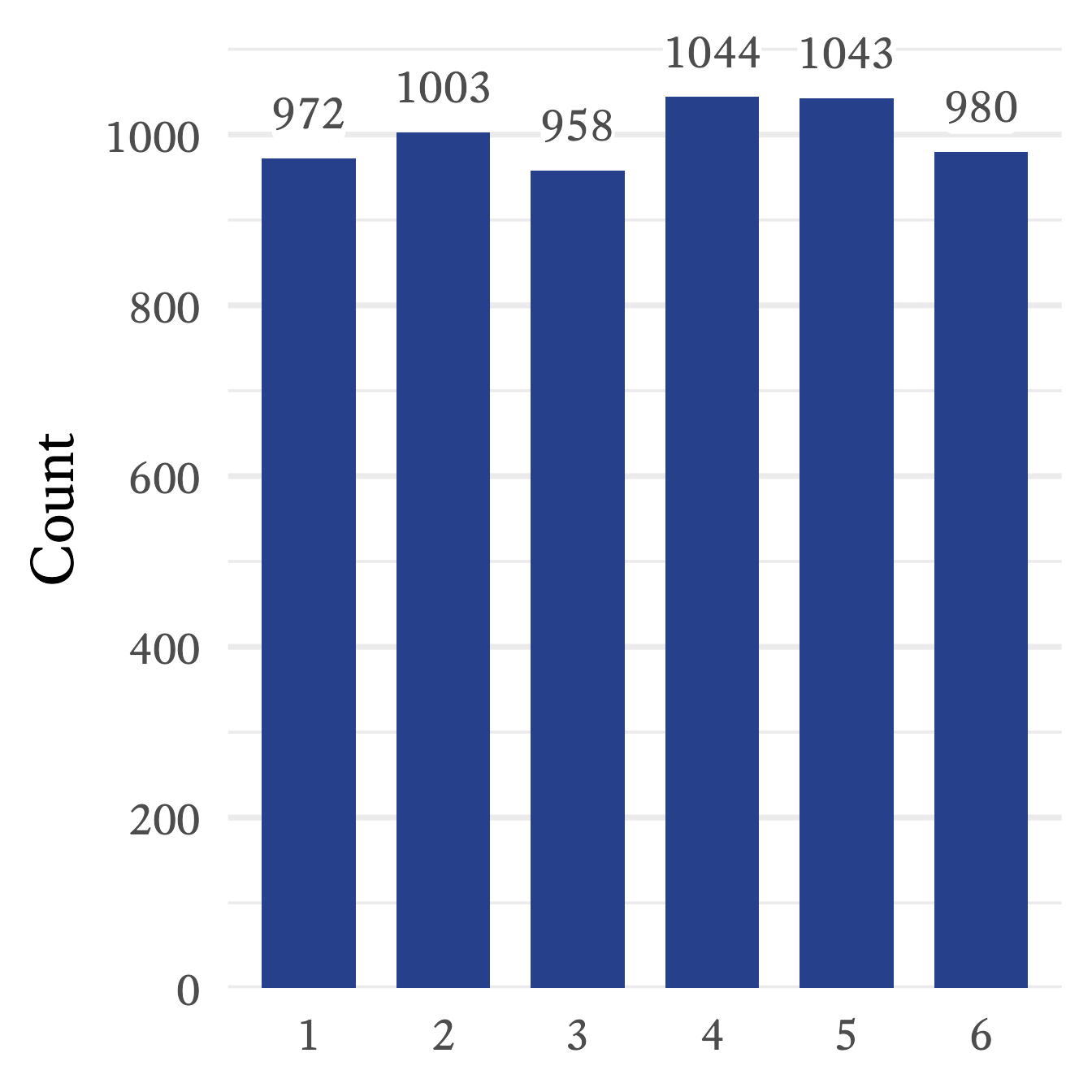
The frequencies of the random sample can be seen in Figure 9.7. Because of sampling error, the frequencies are approximately the same, but not exactly the same. If the sample is larger, the sampling error is smaller, meaning that the sample’s characteristics will tend to more closely resemble the population characteristics. In this case, a larger sample size will produce frequency counts that will appear more even in their magnitude. However, as long as the sample is smaller than the population, sampling error will always be present. With random distributions, the population is assumed to be infinitely large, and thus sampling error at best becomes negligibly small.
9.1.7 Bernoulli Distributions
| Feature | Symbol |
|---|---|
| Sample Space: | x \in \{0,1\} |
| Probability that x=1 | p \in {[0,1]} |
| Probability that x=0 | q = 1 - p |
| Mean | \mu = p |
| Variance | \sigma^2 = pq |
| Skewness | \gamma_1 = \frac{1 - 2p}{\sqrt{pq}} |
| Kurtosis | \gamma_2 = \frac{1}{pq} - 6 |
| Probability Mass Function | f_X(x;p) = p^xq^{1 - x} |
| Cumulative Distribution Function | F_X(x;p) = x+p(1 - x) |
Notation note: Whereas {a,b} is the set of just two numbers, a and b, [a,b] is the set of all real numbers between a and b.
The toss of a single coin has the simplest probability distribution that I can think of—there are only two outcomes and each outcome is equally probable (Figure 9.8). This is a special case of the Bernoulli distribution. Jakob Bernoulli (Figure 9.9) was a famous mathematician from a famous family of mathematicians. The Bernoulli distribution is just one of the ideas that made Jakob and the other Bernoullis famous.
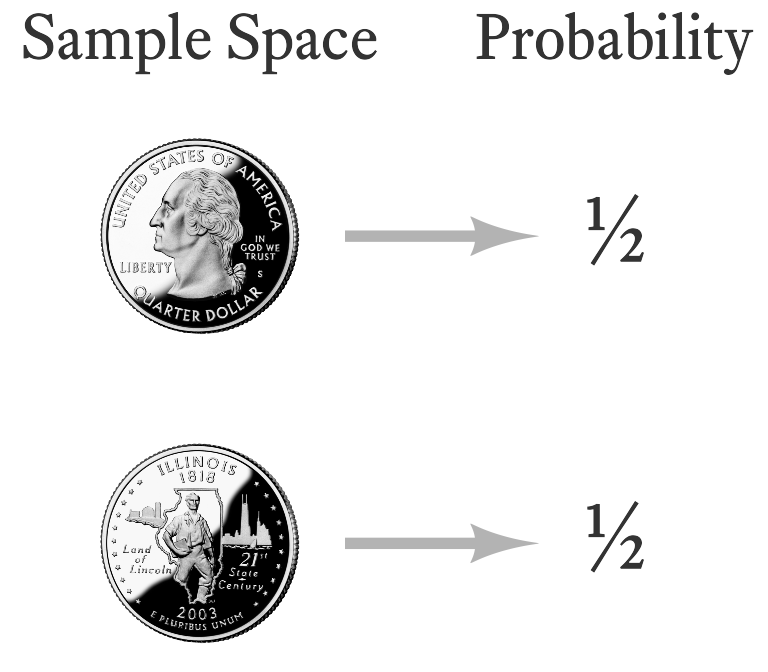

Image Credits
The Bernoulli distribution can describe any random variable that has two outcomes, one of which has a probability p and the other has a probability q=1-p. In the case of a coin flip, p=0.5. For other variables with a Bernoulli distribution, p can range from 0 to 1.
In psychological assessment, many of the variables we encounter have a Bernoulli distribution. In ability test items in which there is no partial credit, examinees either succeed or fail. The probability of success on an item (in the whole population) is p. In other words, p is the proportion of the entire population that correctly answers the question. Some ability test items are very easy and the probability of success is high. In such cases, p is close to 1. When p is close to 0, few people succeed and items are deemed hard. Thus, in the context of ability testing, p is called the difficulty parameter. This is confusing because when p is high, the item is easy, not difficult. Many people have suggested that it would make more sense to call it the easiness parameter, but the idea has never caught on.
True/False and Yes/No items on questionnaires also have Bernoulli distributions. If an item is frequently endorsed as true (“I like ice cream.”), p is high. If an item is infrequently endorsed (“I like black licorice and mayonnaise in my ice cream.”), p is very low. Oddly, the language of ability tests prevails even here. Frequently endorsed questionnaire items are referred to as “easy” and infrequently endorsed items are referred to as “difficult,” even though there is nothing particularly easy or difficult about answering them either way.
9.1.7.1 Generating a Random Sample from the Bernoulli Distribution
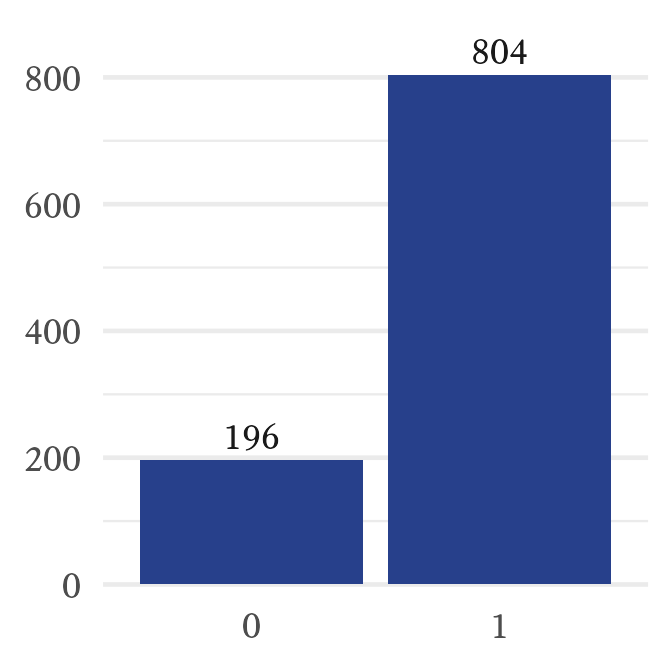
In R, there is no specialized function for the Bernoulli distribution because it turns out that the Bernoulli distribution is a special case of the binomial distribution, which will be described in the next section. With the function rbinom, we can generate data with a Bernoulli distribution by setting the size parameter equal to 1.
In Figure 9.10, we can see that the random variable generated a sequence that consists of about 80% ones and 20% zeroes. However, because of sampling error, the results are rarely exactly what the population parameter specifies.
9.1.8 Binomial Distributions
| Feature | Symbol |
|---|---|
| Number of Trials | n \in \{1,2,3,\ldots\} |
| Sample Space | x \in \{0,...,n\} |
| Probability of success in each trial | p \in [0,1] |
| Probability of failure in each trial | q = 1 - p |
| Mean | \mu = np |
| Variance | \sigma = npq |
| Skewness | \gamma_1 = \frac{1-2p}{\sqrt{npq}} |
| Kurtosis | \gamma_2 = \frac{1}{npq} - \frac{6}{n} |
| Probability Mass Function | f_X(x;n,p)=\frac{n!}{x!\left(n-x\right)!}p^x q^{n-x} |
| Cumulative Distribution Function | F_X(x;n,p)=\sum_{i=0}^{x}{\frac{n!}{i!(n-i)!} p^i q^{n-i}} |

Let’s extend the idea of coin tosses and see where it leads. Imagine that two coins are tossed at the same time and we count how many heads there are. The outcome we might observe will be zero, one, or two heads. Thus, the sample space for the outcome of the tossing of two coins is the set \{0,1,2\} heads. There is only one way that we will observe no heads (both coins tails) and only one way that we will observe two heads (both coins heads). In contrast, as seen in Figure 9.11, there are two ways that we can observe one head (heads-tails & tails-heads).
The probability distribution of the number of heads observed when two coins are tossed at the same time is a member of the binomial distribution family. The binomial distribution occurs when independent random variables with the same Bernoulli distribution are added together. In fact, Bernoulli discovered the binomial distribution as well as the Bernoulli distribution.
Imagine that a die is rolled 10 times and we count how often a 6 occurs.4 Each roll of the die is called a trial. The sample space of this random variable is \{0,1,2,...,10\}. What is the probability that a 6 will occur 5 times? or 1 time? or not at all? Such questions are answered by the binomial distribution’s probability mass function:
4 Wait! Hold on! I thought that throwing dice resulted in a (discrete) uniform distribution. Well, it still does. However, now we are asking a different question. We are only concerned with two outcomes each time the die is thrown: 6 and not 6. This is a Bernoulli distribution, not a uniform distribution, because the probability of the two events is unequal: {⅙,⅚}
f_X(x;n,p)=\frac{n!}{x!\left(n-x\right)!}p^x\left(1-p\right)^{n-x}
| Symbol | Meaning |
|---|---|
| X | The random variable (the number of sixes from 10 throws of the die) |
| x | Any particular member of the sample space (i.e., x \in \{0,1,2,...,10\}) |
| n | The number of times that the die is thrown (i.e., n=10) |
| p | The probability that a six will occur on a single throw of the die (i.e., p=\frac{1}{6}) |
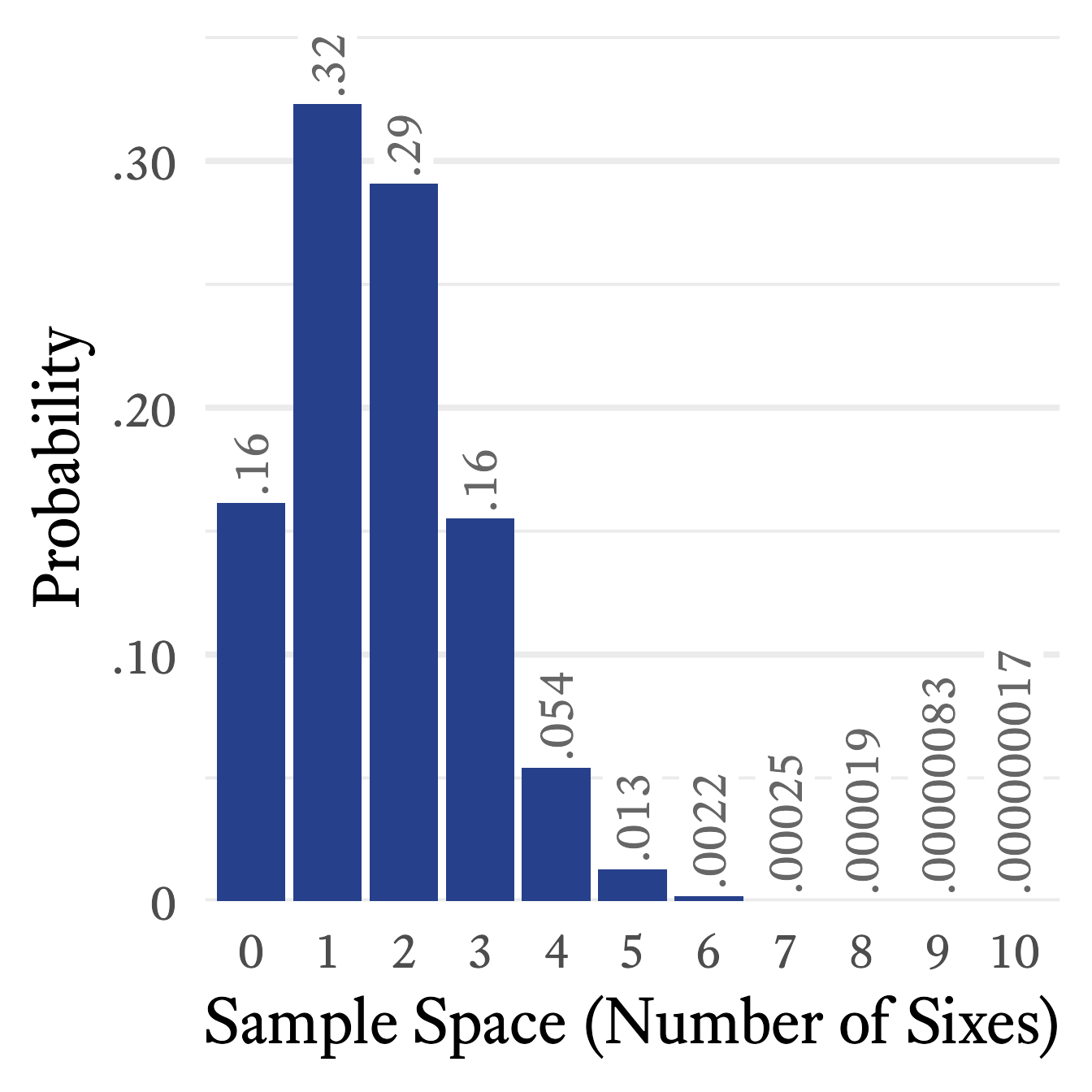
Because n=10 and p=\frac{1}{6}, the probability mass function simplifies to:
\begin{equation*} f_X(x)=\frac{n!}{x!\left(n-x\right)!}\left(\frac{1}{6}\right)^x\left(\frac{5}{6}\right)^{10-x} \end{equation*}
If we take each element x of the sample space from 0 to 10 and plug it into the equation above, the probability distribution will look like Figure 9.12.
9.1.8.1 Clinical Applications of the Binomial Distribution
When would a binomial distribution be used by a clinician? One particularly important use of the binomial distribution is in the detection of malingering. Sometimes people pretend to have memory loss or attention problems in order to win a lawsuit or collect insurance benefits. There are a number of ways to detect malingering but a common method is to give a very easy test of memory in which the person has at least a 50% chance of getting each test item correct even if the person guesses randomly.
Suppose that there are 20 questions. Even if a person has the worst memory possible, that person is likely to get about half the questions correct. However, it is possible for someone with a legitimate memory problem to guess randomly and by bad luck answer fewer than half of the questions correctly. Suppose that a person gets 4 questions correct. How likely is it that a person would, by random guessing, only answer 4 or fewer questions correctly?
We can use the binomial distribution’s cumulative distribution function. However, doing so by hand is rather tedious. Using R, the answer is found with the pbinom function:
p <- pbinom(4,20,0.5)We can see that the probability of randomly guessing and getting 4 or fewer items correct out of 20 items total is approximately 0.006, which is so low that the hypothesis that the person is malingering seems plausible. Note here that there is a big difference between these two questions:
- If the person is guessing at random (i.e., not malingering), what is the probability of answering correctly 4 questions or fewer out of 20?
- If the person answers 4 out of 20 questions correctly, what is the probability that the person is guessing at random (and therefore not malingering)?
Here we answer only the first question. It is an important question, but the answer to the second question is probably the one that we really want to know. We will answer it in another chapter when we discuss positive predictive power. For now, we should just remember that the questions are different and that the answers can be quite different.
9.1.8.2 Graphing the binomial distribution
Suppose that there are n=10 trials, each of which have a probability of p=0.8. The sample space is the sequence of integers from 0 to 10, which can be generated with the seq function (i.e., seq(0,10)) or with the colon operator 0:10. First, the sample space is generated (a sequence from 0 to 10.), using the seq function. The associated probability mass function probabilities are found using the dbinom function. The cumulative distribution function probabilities are found using the pbinom function.
# Make a sequence of numbers from 0 to 10
SampleSpace <- seq(0, 10)
# Probability mass distribution for
# binomial distribution (n = 10, p = 0.8)
pmfBinomial <- dbinom(SampleSpace,
size = 10,
prob = 0.8)
# Generate a basic plot of the
# probability mass distribution
plot(pmfBinomial ~ SampleSpace,
type = "b")
# Cumulative distribution function
# for binomial distribution (n = 10, p = 0.8)
cdfBinomial <- pbinom(SampleSpace,
size = 10,
prob = 0.8)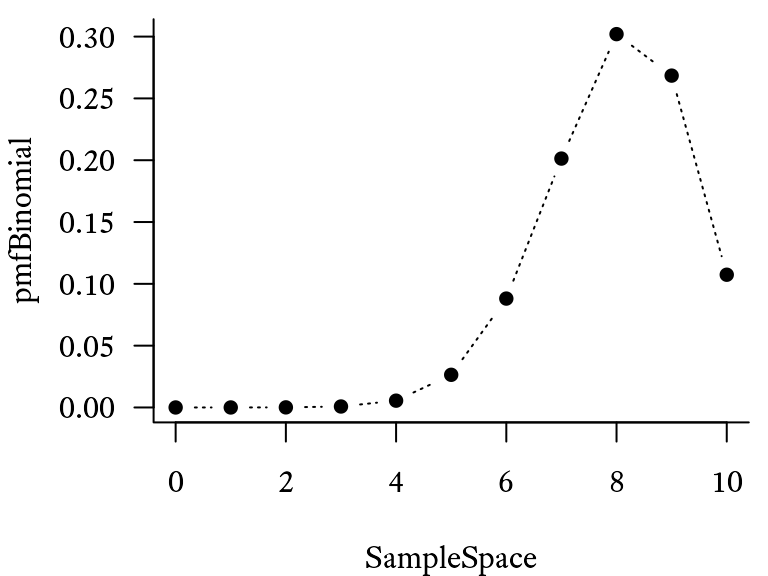
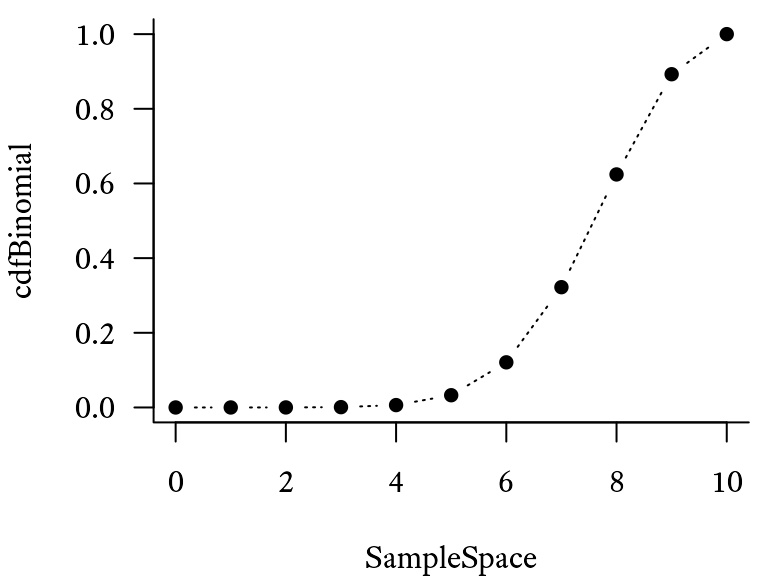
However, making the graph look professional involves quite a bit of code that can look daunting at first. However, the results are often worth the effort. Try running the code below to see the difference. For presentation-worthy graphics, export the graph to the .pdf or .svg format. An .svg file can be imported directly into MS Word or MS PowerPoint.
Warning in geom_pointline(lty = "dotted", distance = unit(3, "mm")):
`geom_pointpath` and `geom_pointline` have been soft-deprecated. A replacement
can be found in ggh4x::geom_pointpath.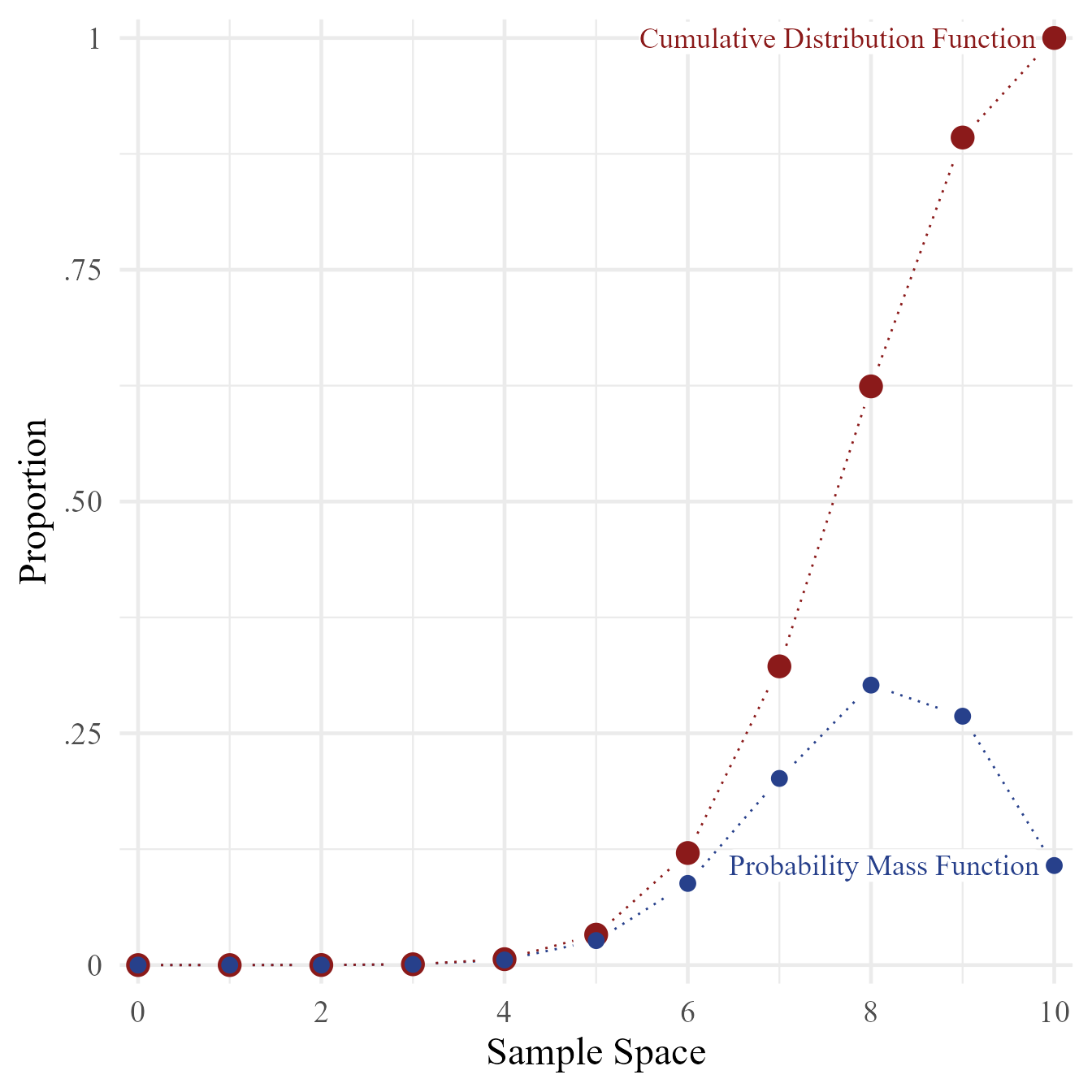
9.1.9 Poisson Distributions
| Feature | Symbol |
|---|---|
| Parameter | \lambda \in (0,\infty) |
| Sample Space | x\in \{0,1,2,\ldots\} |
| Mean | \mu = \lambda |
| Variance | \sigma^2 = \lambda |
| Skewness | \gamma_1 = \frac{1}{\sqrt{\lambda}} |
| Kurtosis | \gamma_2 = \frac{1}{\lambda} |
| Probability Mass Function | f_X(x;\lambda) = \frac{\lambda^x}{e^{\lambda} x!} |
| Cumulative Distribution Function | F_X(x;\lambda) = \sum_{i=0}^{x}{\frac{\lambda^i}{e^{\lambda} i!}} |
Notation note: The notation (0,\infty) means all real numbers greater than 0.

Image Credits
Imagine that an event happens sporadically at random and we measure how often it occurs in regular time intervals (e.g., events per hour). Sometimes the event does not occur in the interval, sometimes just once, and sometimes more than once. However, we notice that over many intervals, the average number of events is constant. The distribution of the number of events in each interval will follow a Poisson distribution. Although “Poisson” means “fish” in French, fish have nothing to do with it. This distribution was named after Siméon Denis Poisson, whose work on the distribution made it famous.
The Poisson distribution has a single parameter \lambda, the average number of events per time interval. Interestingly, \lambda is both the mean and the variance of this distribution. The distribution shape will differ depending on how long our interval is. If an event occurs on average 30 times per hour, \lambda = 30. If we count how often the event occurs in 10-minute intervals, the same event will occur about 5 times per interval, on average (i.e., \lambda = 1). If we choose to count how often the same event occurs every minute, then \lambda = 0.5.
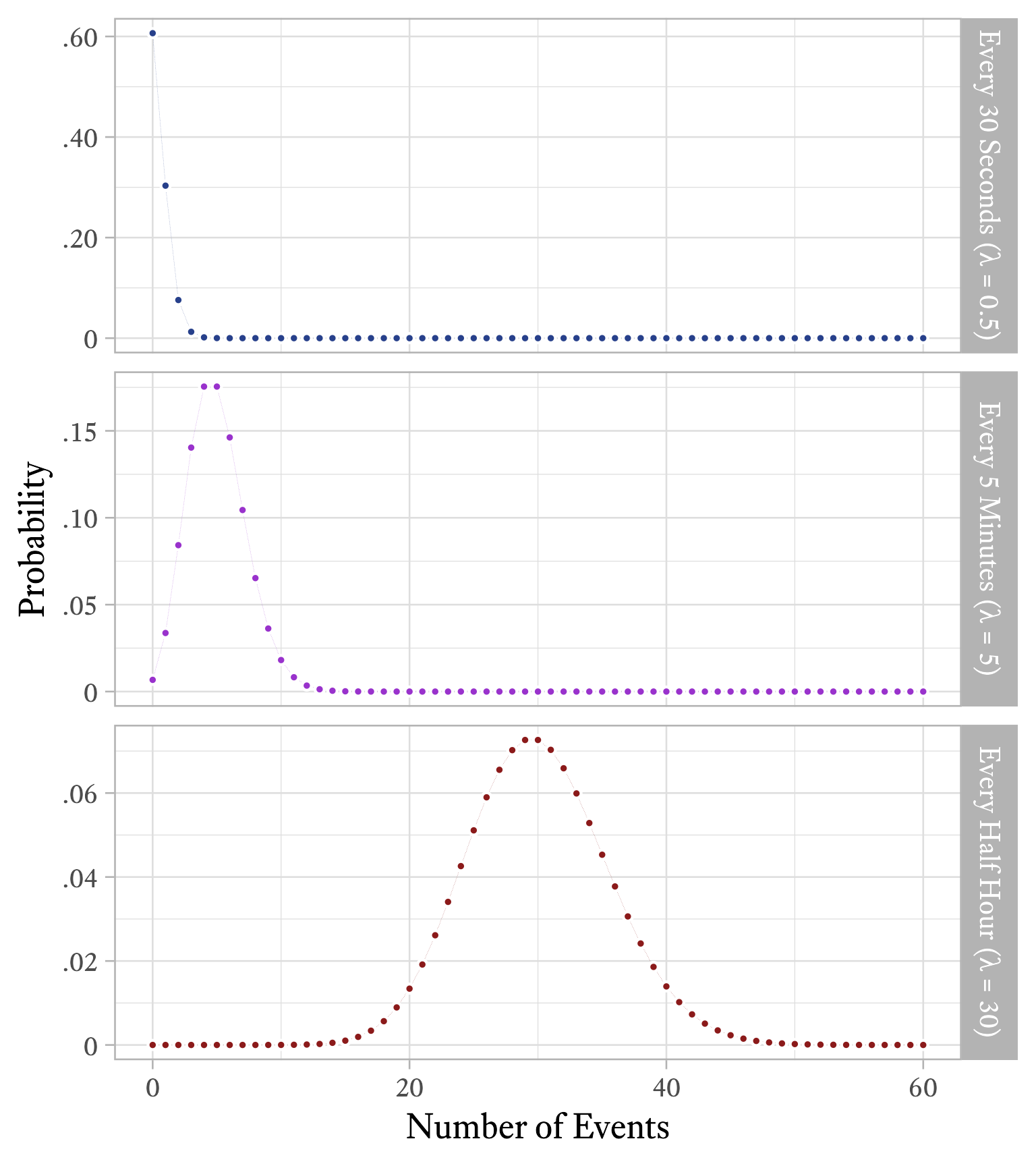
9.1.9.1 A clinical application of the the Poisson distribution
Suppose that you begin treating an adult male client who has panic attacks that come at unpredictable times. Some weeks there are no panic attacks and some weeks there are many, but on average he has 2 panic attacks each week. The client knows this because he has kept detailed records in a spreadsheet for the last 5 years. The client had sought treatment once before, but terminated early and abruptly because, according to him, “It wasn’t working.” After sensitive querying, you discover that he expected that treatment should have quickly reduced the frequency of panic attacks to zero. When that did not happen, he became discouraged and stopped the treatment.
Because your client is well educated and quantitatively inclined, you decide to to use the data he has collected as part of the intervention and also to help set a more realistic set of expectations. Obviously, you and your client both would prefer 0 panic attacks per week, but sometimes it takes more time to get to the final goal. We do not want to terminate treatment that is working just because the final goal has not yet been achieved.
You plot the frequency of how often he had 0 panic attacks in a week, 1 panic attack in a week, 2 panic attacks in a week, and so forth, as shown in red in Figure 9.18. Because you have read this book, you immediately recognize that this is a Poisson distribution with \lambda = 2. When you graph an actual Poison distribution and compare it with your client’s data, you see that it is almost a perfect match.5 Then you explain that although the goal is permanent cessation of the panic attacks, sometimes an intervention can be considered successful if the frequency of panic attacks is merely reduced. For example, suppose that in the early stages of treatment the frequency of panic attacks were reduced from twice per week to once every other week (\lambda = 0.5), on average. If such a reduction were achieved, there would still be weeks in which two or more panic attacks occur. According to Figure 9.21, this will occur about 9% of the time.
5 Note that I am not claiming that all clients’ panic attack frequencies have this kind of distribution. It just so happens to apply in this instance.
Warning in geom_pointline(linetype = "dotted", linesize = 0.5, size = 3, :
`geom_pointpath` and `geom_pointline` have been soft-deprecated. A replacement
can be found in ggh4x::geom_pointpath.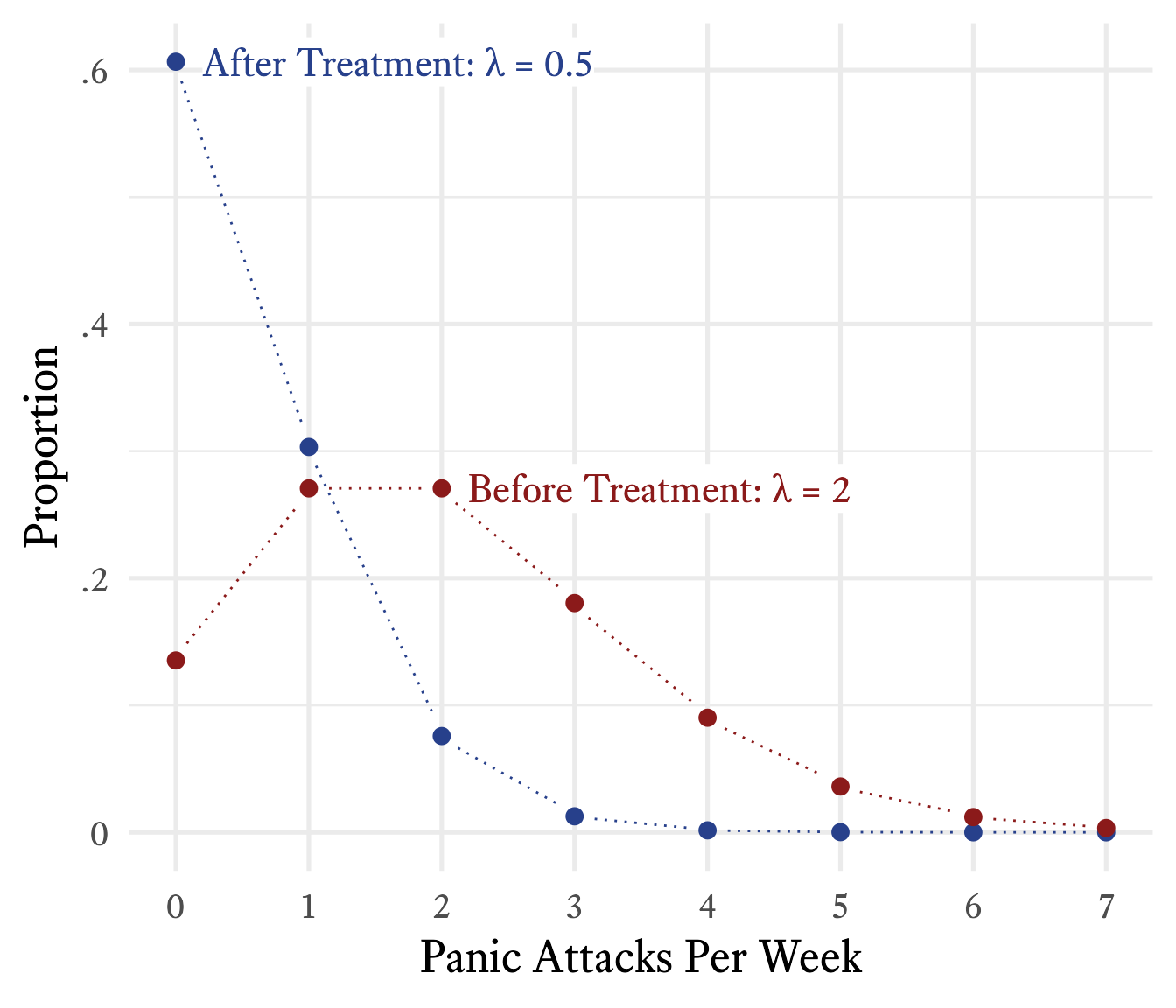
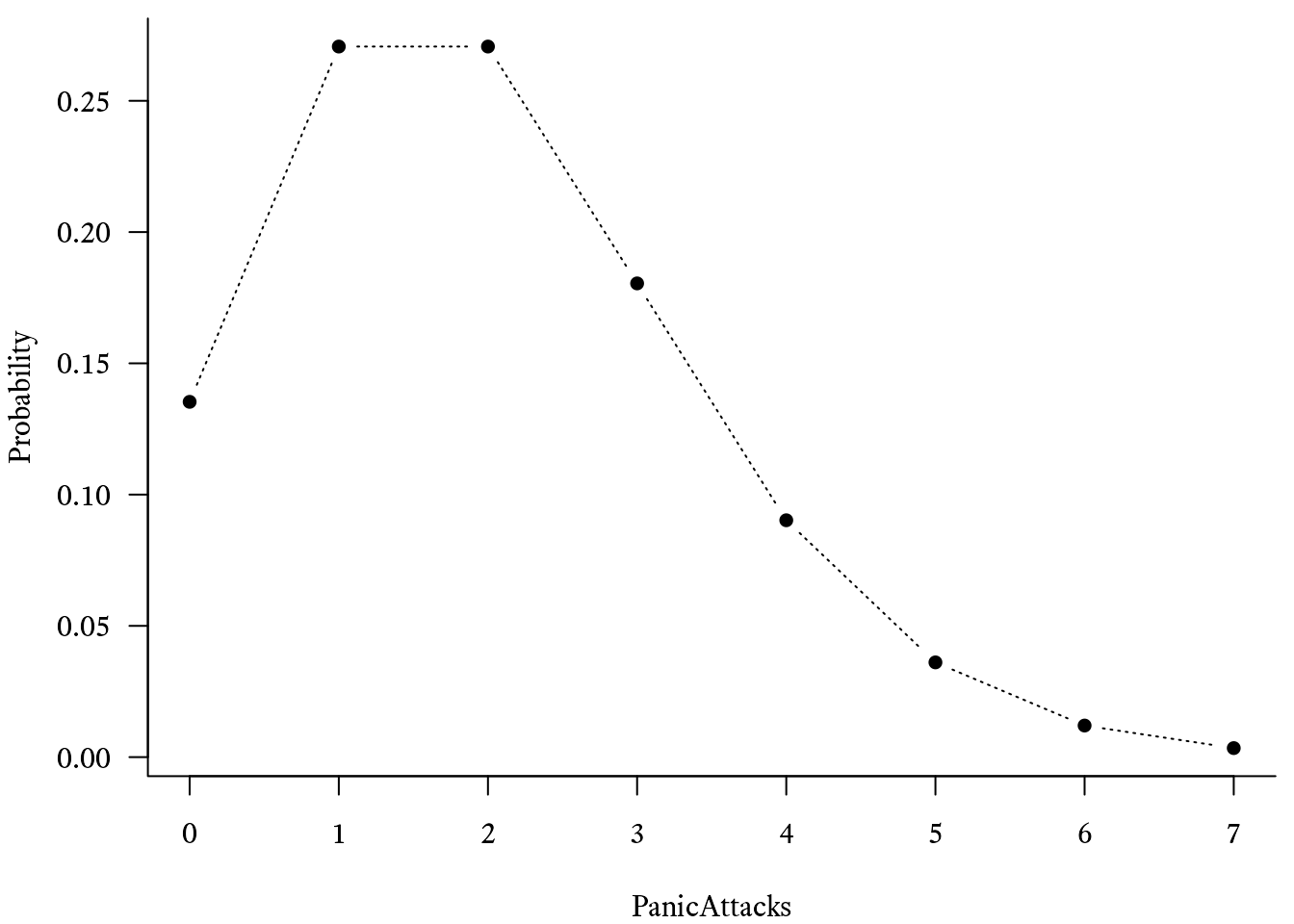
In R, you can use the dpois function to plot the Poisson probability mass function. For example, if the average number of events per time period is λ = 2, then the probability that there will be 0 events is dpois(x = 0, lambda = 2), which evaluates to 0.1353.
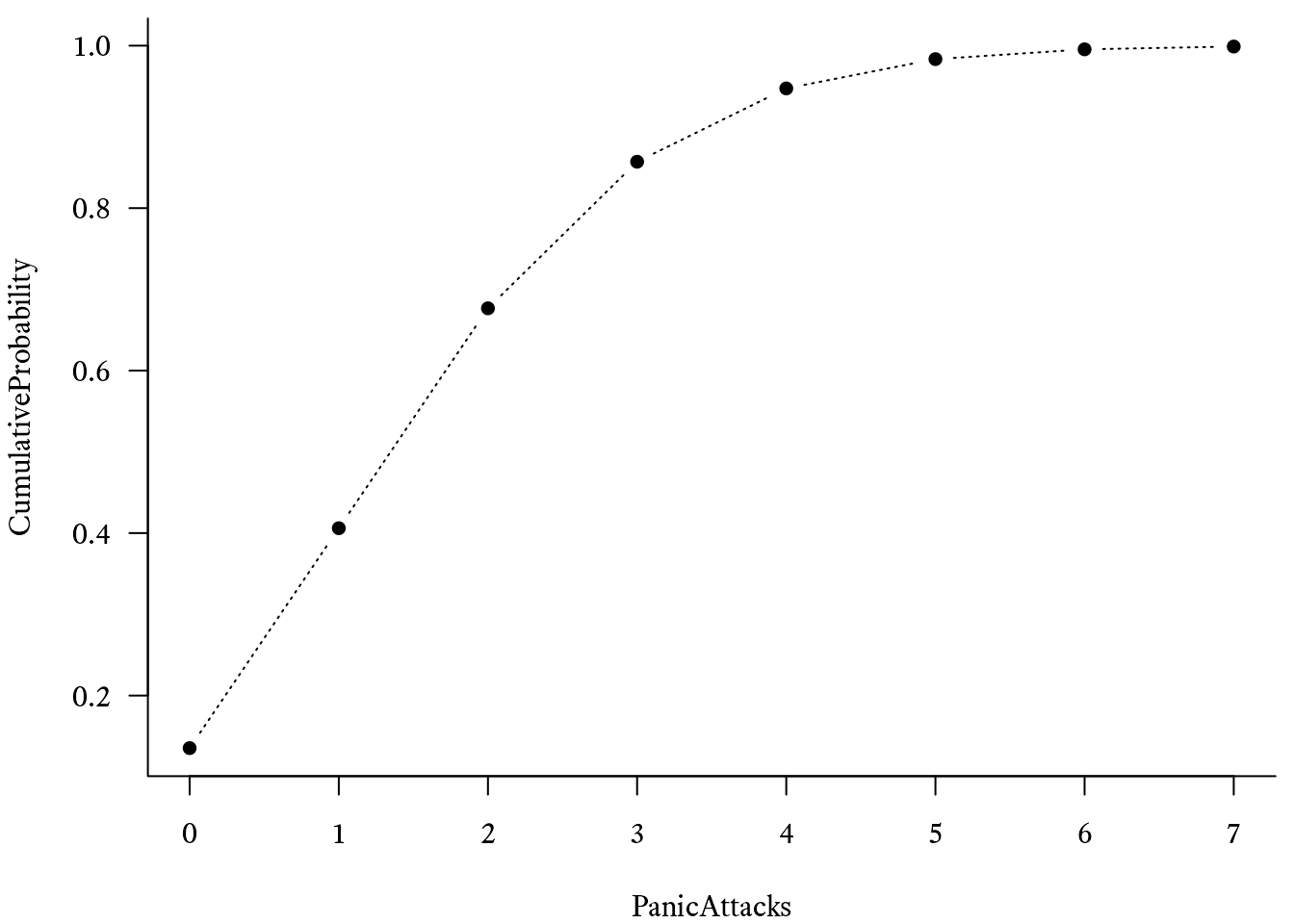
To calculate the cumulative distribution function of Poisson distribution in R, use the ppois function. For example, if we want to estimate the probability of having 4 panic attacks or more in a week if λ = 2, we must subtract the probability of having 3 panic attacks or less from 1, like so:
1 - ppois(q = 3, lambda = 2)p = 0.143
Here is a simple way to plot the probability mass function and the cumulative distribution function using the dpois and ppois functions:
With an additional series with \lambda = 0.5, the plot can look like Figure 9.21.
Warning in geom_pointline(linetype = "dotted", linesize = 0.5, size = 3, :
`geom_pointpath` and `geom_pointline` have been soft-deprecated. A replacement
can be found in ggh4x::geom_pointpath.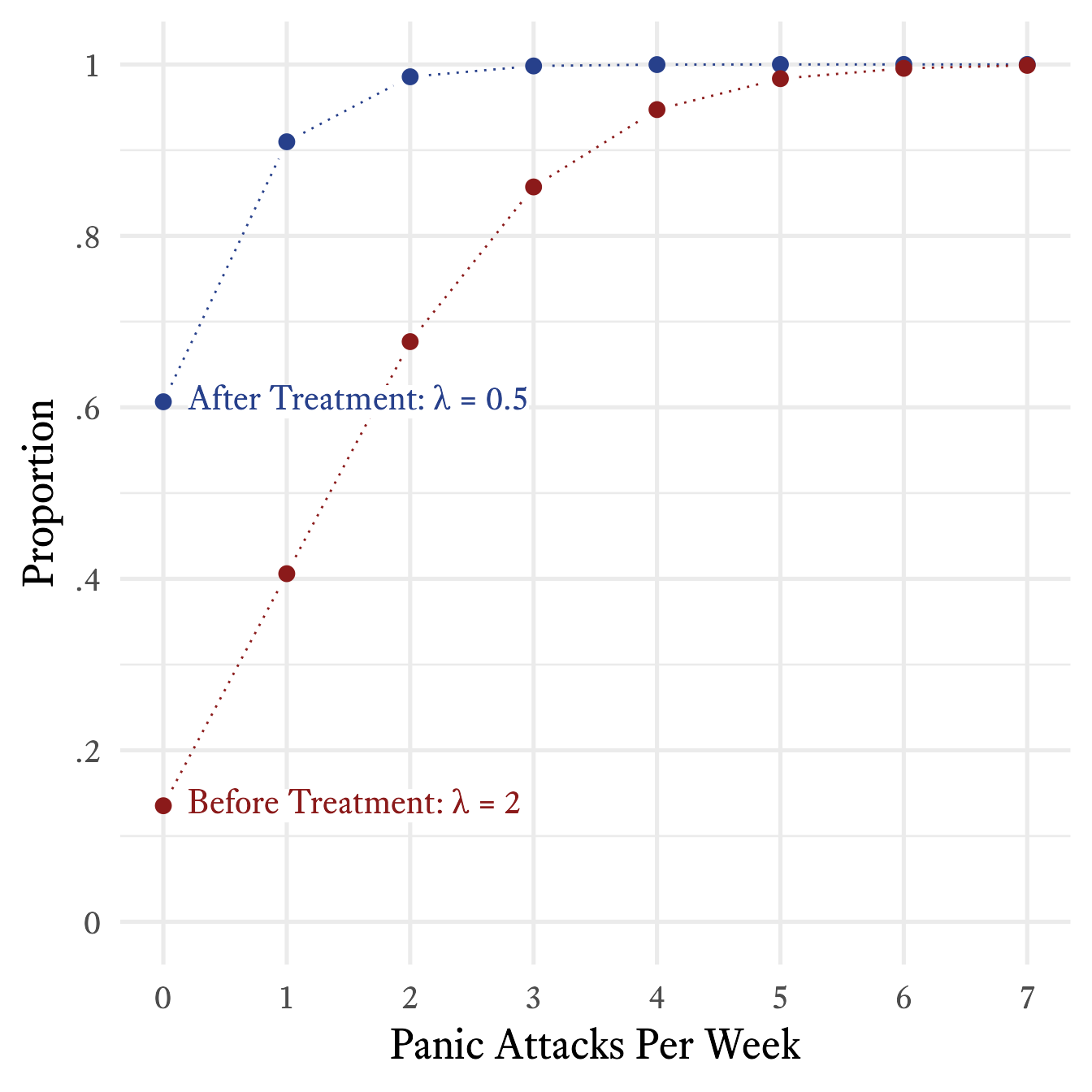
9.1.10 Geometric Distributions
| Feature | Symbol |
|---|---|
| Probability of success in each trial | p\in[0,1] |
| Sample Space | x \in \{1,2,3,\ldots\} |
| Mean | \mu = \frac{1}{p} |
| Variance | \sigma^2 = \frac{1-p}{p^2} |
| Skewness | \gamma_1 = \frac{2-p}{\sqrt{1-p}} |
| Kurtosis | \gamma_2 = 6 + \frac{p^2}{1-p} |
| Probability Mass Function | f_X(x;p) = (1-p)^{x-1}p^x |
| Cumulative Distribution Function | F_X(x;p) = 1-(1-p)^x |
Atul Gawande (2007, pp. 219–223) tells a marvelous anecdote about how a doctor used some statistics to help a young patient with cystic fibrosis to return to taking her medication more regularly. Because the story is full of pathos and masterfully told, I will not repeat a clumsy version of it here. However, unlike Gawande, I will show how the doctor’s statistics were calculated.
According to the story, if a patient fails to take medication, the probability that a person with cystic fibrosis will develop a bad lung illness on any particular day is .005. If medication is taken, the risk is .0005. Although these probabilities are both close to zero, over the the course of a year, they result in very different levels of risk. Off medication, the patient has about an 84% chance of getting sick within a year’s time. On medication, the patient’s risk falls to 17%. As seen in Figure 9.22, the cumulative risk over the course of 10 years is quite different. Without medication, the probability of becoming seriously ill within 10 years at least once is almost certain. With medication, however, a small but substantial percentage (~16%) of patients will go at least 10 years without becoming ill.
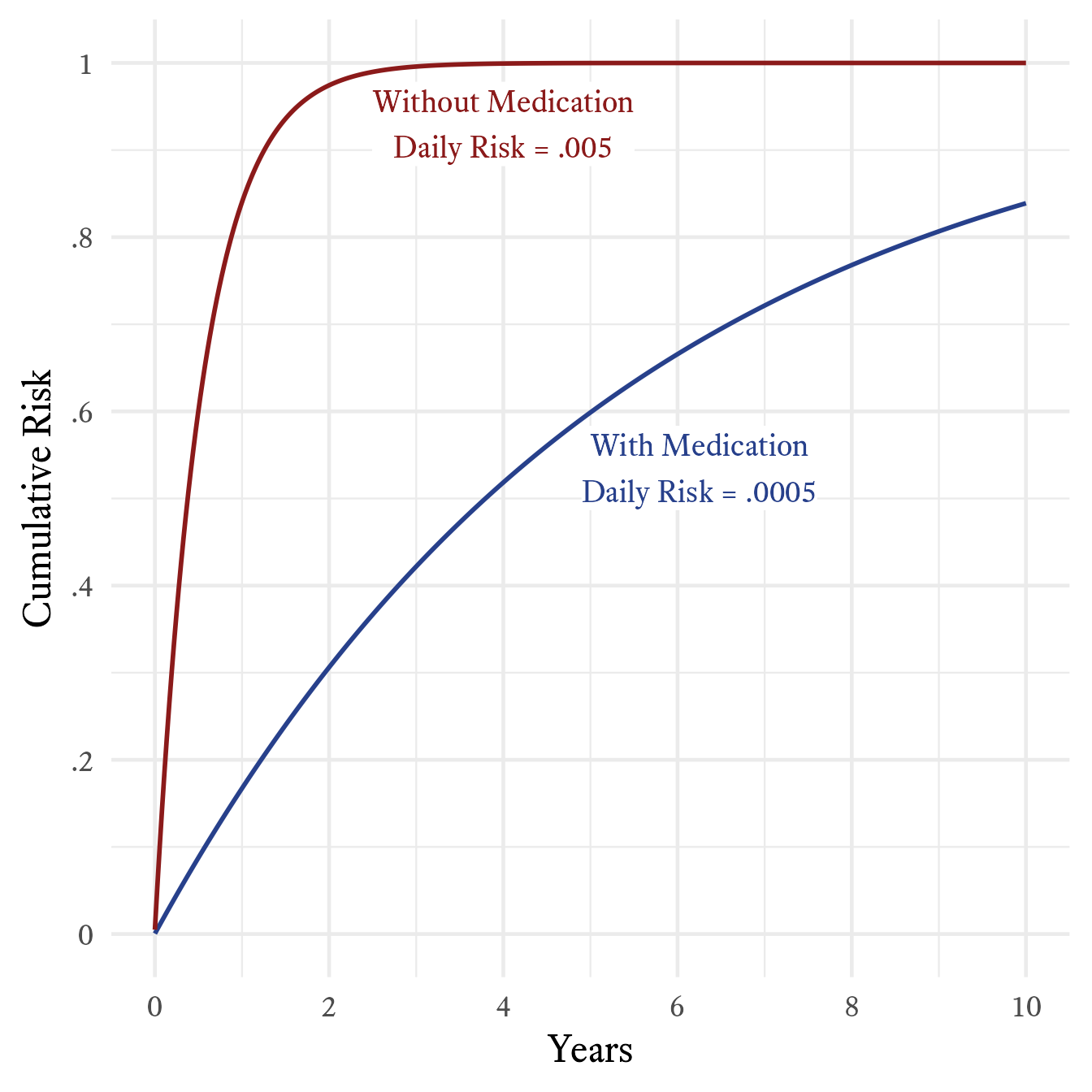
Such calculations make use of the geometric distribution. Consider a series of Bernoulli trials in which an event has a probability p of occurring on any particular trial. The probability mass function of the geometric distribution will tell us the probability that the xth trial will be the first time the event occurs.
f_X(x;p)=(1-p)^{x-1}p^x
| Symbol | Meaning |
|---|---|
| X | A random variable with a geometric distribution |
| f_X | The probability mass function of X |
| x | The number of Bernoulli trials on which the event first occurs |
| p | The probability of an event occurring on a single Bernoulli trial |
In R, the probability mass function of the geometric distribution is calculated with the dgeom function:
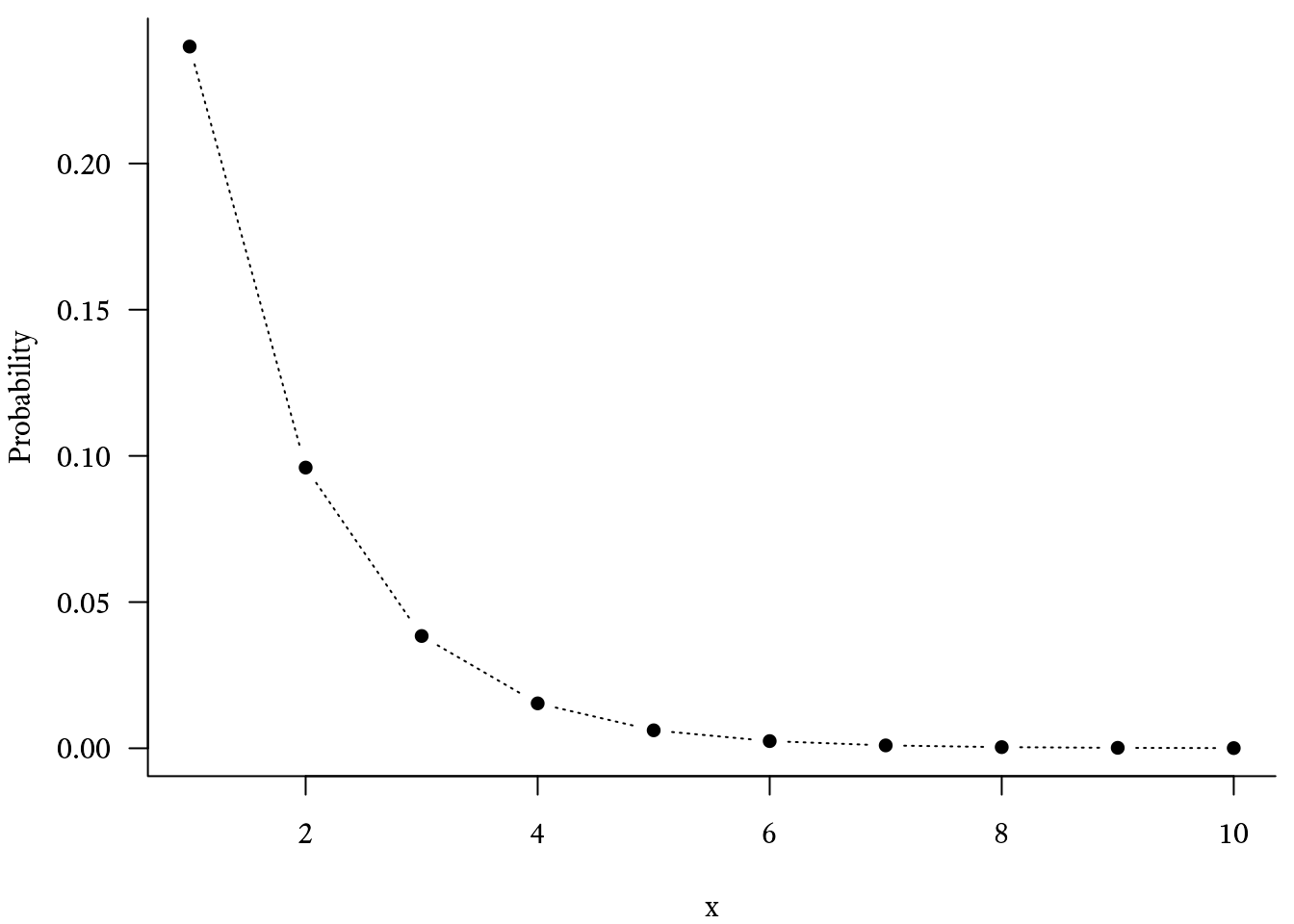
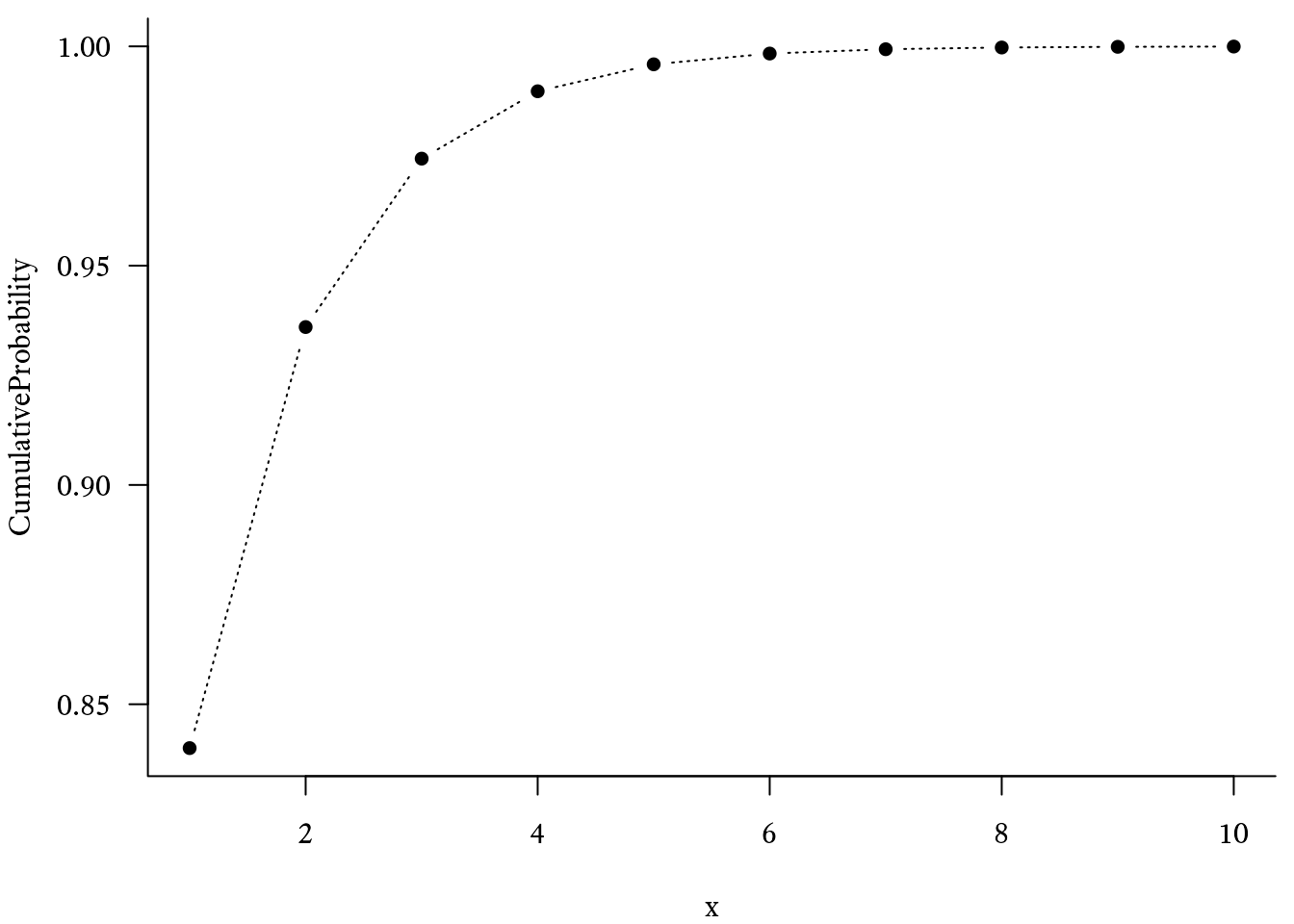
The cumulative distribution function of the geometric distribution was used to create Figure 9.22. It tells us the probability that the event will occur on the x^{th} trial or earlier:
F_X(x;p)=1-(1-p)^x
In R, the cumulative distribution function of the geometric distribution uses the pgeom function:
{kind=link}
{kind=link}