11 Descriptives
When we encounter a large list of unsorted numbers, we have no natural capacity to perceive fundamental characteristics of the list, such as its average or its variability. Therefore, we need descriptive statistics to quantify salient characteristics of distributions, or we need to display the numbers in a plot, making them easier to understand and communicate.
11.1 Frequency Distribution Tables
A simple way to describe a distribution is to list how many times each value in the distribution occurs. For example, in this distribution: \{10, 3, 4, 10, 6, 4, 6, 4\}, there is 1 three, 3 fours, 2 sixes, and 2 tens. The value that occurs most often is four. A frequency distribution table displays the number of times each value occurs, as in Table 11.1.
Value |
Frequency |
Cumulative |
Proportion |
Cumulative |
|---|---|---|---|---|
3 |
1 |
1 |
.125 |
.125 |
4 |
3 |
4 |
.375 |
.500 |
6 |
2 |
6 |
.250 |
.750 |
10 |
2 |
8 |
.250 |
1 |
The median is 5, halfway between the two middle scores of 4 and 6.
It is common to include alongside the frequencies of each value the proportion (or percentage) of times a value occurs. If the frequency of sample space element i is f_i, and the total sample size is n, then the proportion of sample space element i is
p_i = \frac{f_i}{n}
In Table 11.1, the frequency of sixes is f=2 and there are n = 8 numbers in the distribution, thus the proportion of sixes is p = \frac{2}{8} = .25.
It is also common to supplement frequency distribution tables with additional information such as the cumulative frequency. For each sample space element, the cumulative frequency (cf) is the sum of the frequencies (f) of the current and all previous sample space elements.
cf_i= \sum_{j=1}^{i}{f_j}
Ordinal, interval, and ratio variables can have cumulative frequencies, but not nominal variables. To calculate cumulative frequencies, the sample space needs to be sorted in a meaningful way, which is not possible with true nominal variables. That is, there are no scores “below” any other scores in nominal variables.
The cumulative proportion (cp) is the proportion of scores less than or equal to a particular sample space element.
cp_i = \frac{cf_i}{n}
11.1.1 Frequency Distribution Tables in R
Let’s start with a data set from Garcia et al. (2010), which can accessed via the psych package.
# Get the Garcia data set from the psych package
d <- psych::GarciaThe sjmisc package (Lüdecke, 2025) provides a quick and easy way to create a frequency distribution table with the frq function.
sjmisc::frq(d$anger)x <numeric>
# total N=129 valid N=129 mean=2.12 sd=1.66
Value | N | Raw % | Valid % | Cum. %
-------------------------------------
1 | 73 | 56.59 | 56.59 | 56.59
2 | 24 | 18.60 | 18.60 | 75.19
3 | 4 | 3.10 | 3.10 | 78.29
4 | 8 | 6.20 | 6.20 | 84.50
5 | 12 | 9.30 | 9.30 | 93.80
6 | 7 | 5.43 | 5.43 | 99.22
7 | 1 | 0.78 | 0.78 | 100.00
<NA> | 0 | 0.00 | <NA> | <NA>Typically we use frequency distribution tables to check whether the values of a variable are correct and that the distribution makes sense to us. Thus the frq function is all we need most of the time. However, if you need a publication-ready frequency distribution table, you will probably have to make it from scratch (See Table 11.2).
*X* *f* *cf* *p* *cp*
1 1 73 73 .57 .57
2 2 24 97 .19 .75
3 3 4 101 .03 .78
4 4 8 109 .06 .84
5 5 12 121 .09 .94
6 6 7 128 .05 .99
7 7 1 129 .01 1.00 f = Frequency,cf = Cumulative Frequency, p = Proportion, and cp = Cumulative Proportion
11.1.2 Frequency Distribution Bar Plots
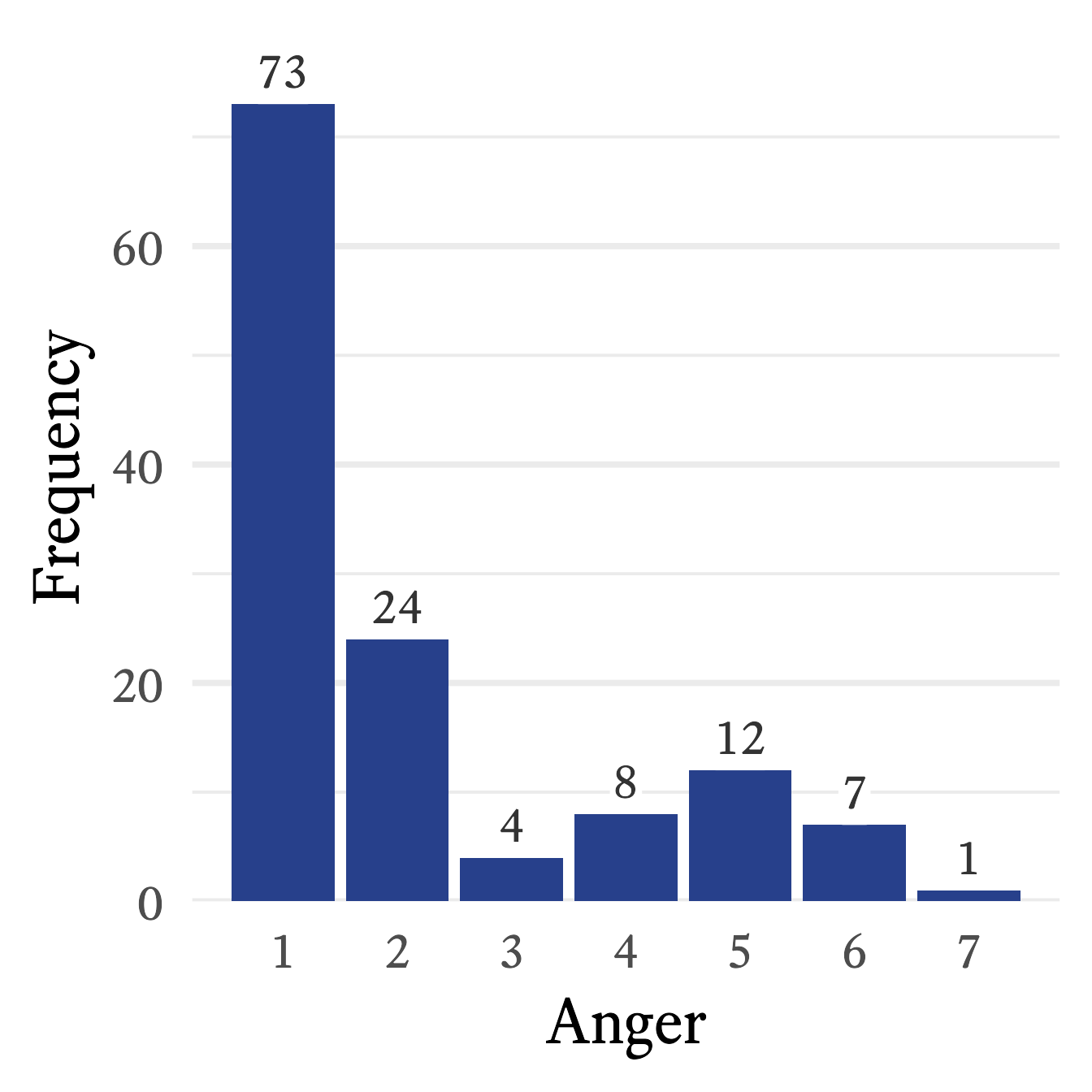
In Figure 11.1, the frequency distribution from Table 11.2 is translated into a standard bar plot in which each bar is proportional to the frequency of each response. A column bar plot allows for easy comparison of the frequency of each category. For example, in Figure 11.1, the most frequent response to the Anger question—1 (low)—draws your attention immediately. In contrast to the mental effort needed to scan frequencies listed in a table, the relative height of each frequency in the bar plot is perceived, compared, and interpreted almost effortlessly. With a single glance at Figure 11.1, no calculation is required to know that none of the other responses is even half as frequent as 1.
11.1.3 Frequency Distribution Stacked Bar Plots
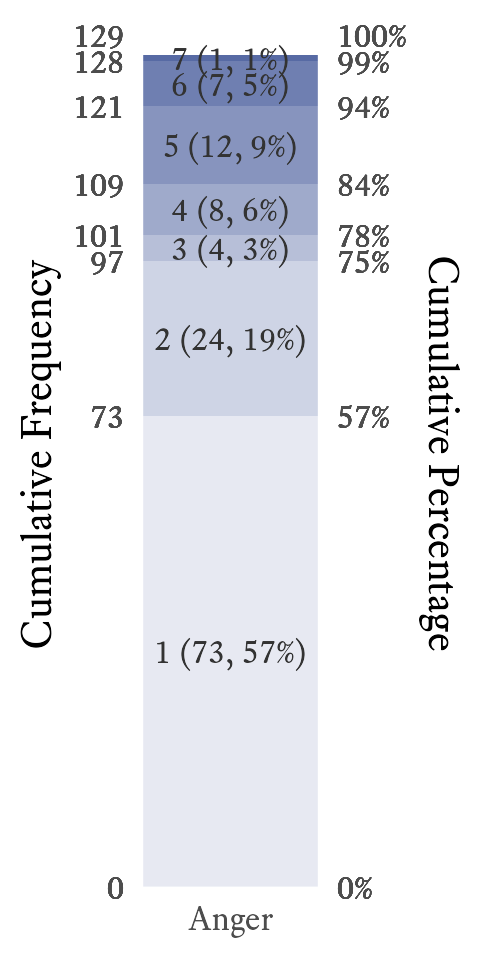
In a standard bar plot, one may easily compare frequencies to each other, but that may not be what you wish the reader to notice first. A stacked bar plot emphasizes the proportions of each category as it relates to the whole. It also allows for the visual display of the cumulative frequencies and proportions. For example, in Figure 11.2, it is easy to see that more than half of participants have an anger level of 1, and three quarters have an anger level of 2 or less.
11.1.4 Frequency Distribution Step Line Plots
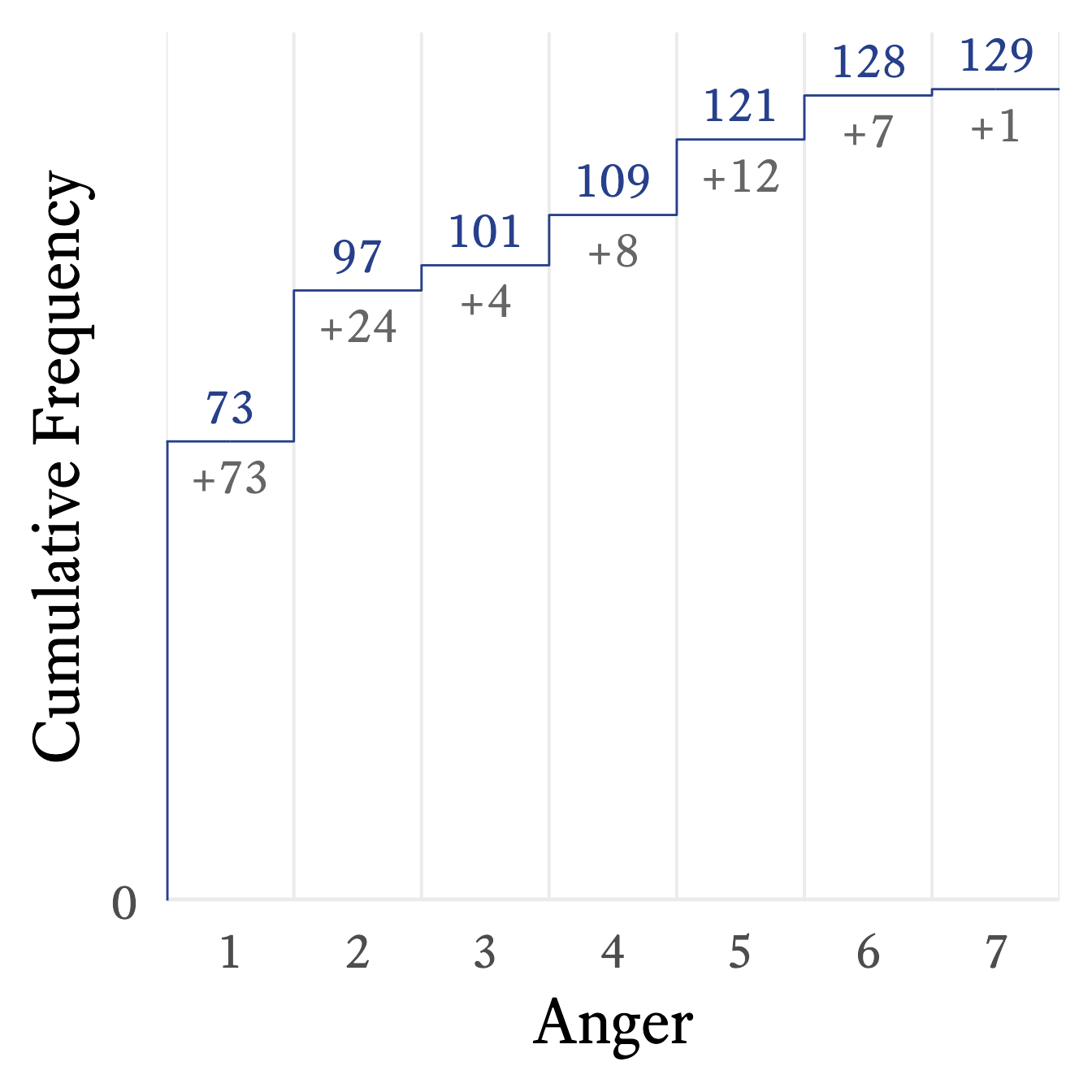
A step line plot can show the cumulative frequency’s relationship with the variable. For example, in Figure 11.3, it appears that the cumulative frequency rises quickly at first but then rises slowly and steadily thereafter.
11.2 Measures of Central Tendency
If we need to summarize an entire distribution with a single number with the least possible information loss, we use a measure of central tendency—usually the mode, the median, or the mean. Although these numbers are intended to represent the entire distribution, they often require accompaniment from other statistics to perform this role with sufficient fidelity.
Our choice of which measure of central tendency we use to summarize a distribution depends on which type of variable we are summarizing (i.e., nominal, ordinal, interval, or ratio) and also a consideration of each central tendency measure’s strengths and weaknesses in particular situations.
11.2.1 Mode
The mode is the most frequent score in a distribution. Suppose we have a distribution that looks like this:
\{1,2,2,2,2,3,3\}
Because 2 occurs more frequently than the other values in the distribution, the mode is 2.
In a frequency distribution table, the mode is the value with the highest value in the f (frequency) column. In Table 11.2, the mode is 1 because it has the highest frequency (f = 73).
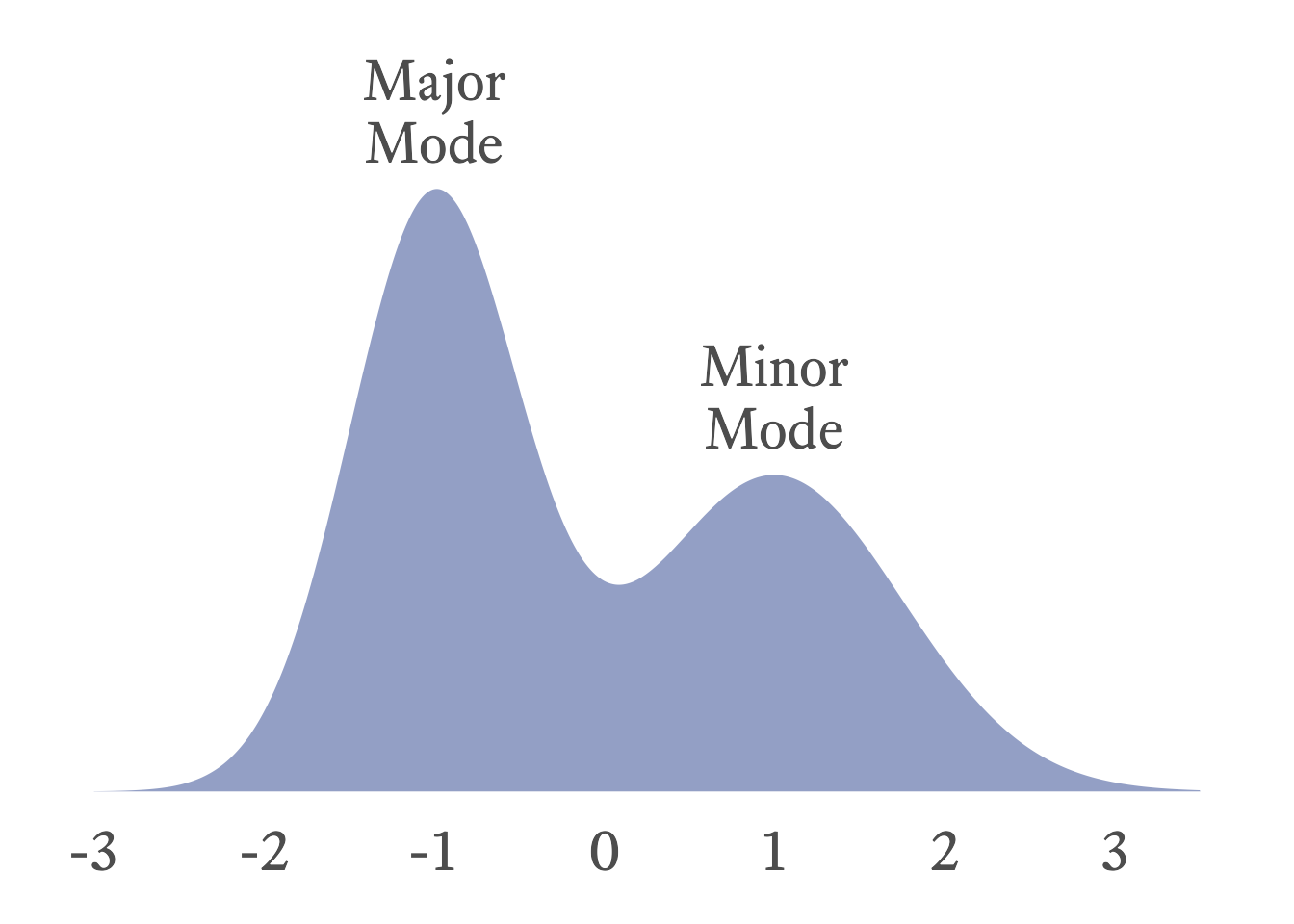
In a bar plot, histogram, or probability density plot, the mode is the value that corresponds to the highest point in the plot. For example, in Figure 11.1, the modal value is 1 because its frequency of 73 is the highest point in the bar plot. In Figure 11.4, the mode is −1 because that is the highest point in the density plot.
If two values tie, both values are the mode and the distribution is bimodal. Sometimes a distribution has two distinct clusters, each with its own local mode. The greater of these two modes is the major mode, and the lesser is the minor mode (See Figure 11.4).
The mode is the only measure of central tendency that be computed for all variable types and is the only choice for nominal variables (See Table 11.4).
To compute the mode of a variable, use the mfv (most frequent value) function from the modeest package (Poncet, 2019). In this example, the 2 occurs four times.
The mfv function will return all modes if there is more than one. In this example, the 1, 3, and 4 all occur twice.
11.2.2 Median
The median is midpoint of a distribution, the point that divides the lower half of the distribution from the upper half. To calculate the median, you first need to sort the scores. If there is an odd number of scores, the median is the middle score. If there an even number of scores, it is the mean of the two middle scores. There are other definitions of the median that are a little more complex, but rarely is precision needed for calculating the median.
To find the median using a frequency distribution table, find the first sample space element with a cumulative proportion greater than 0.5. For example, in the distribution shown in Table 11.3, the first cumulative proportion greater than 0.5 occurs at 5, which is therefore the median.
| X | Frequency | Cumulative Frequency | Proportion | Cumulative Proportion |
|---|---|---|---|---|
| 1 | 1 | 1 | .14 | .14 |
| 5 | 3 | 4 | .43 | .57 |
| 7 | 1 | 5 | .14 | .71 |
| 9 | 2 | 7 | .29 | 1 |
In this case, the median is 5 because it has the first cumulative proportion that is greater than 0.5.
If a sample space element’s cumulative proportion is exactly 0.5, average that sample space element with the next highest value. For example, in the distribution in Table 11.1, the cumulative proportion for 4 is exactly 0.5 and the next value is 6. Thus the median is
\frac{4+6}{2}=5
The median can be computed for ordinal, interval, and ratio variables, but not for nominal variables (See Table 11.4). Because nominal variables have no order, no value is “between” any other value. Thus, because the median is the middle score and nominal variables have no middle, nominal variables cannot have a median.
For ordinal variables, the median is the preferred measure of central tendency because it is usually more stable from one sample to the next compared to the mode.
In R, the median function can compute the median:
11.2.3 Mean
The arithmetic mean is the sum of all values of a distribution divided by the size of the distribution.
\mu_X = \frac{\sum_{i=1}^n {X_i}}{n}
Where \begin{align*} \mu_X &= \text{The population mean of } X\\ n &= \text{The number of values in } X \end{align*}
The arithmetic mean can only be calculated with interval or ratio variables. Why? The formula for the mean requires adding numbers, and the operation of addition is not defined for ordinal and nominal values.
The arithmetic mean is usually the preferred measure of central tendency for interval and ration variables because it is usually more stable from sample to sample than the median and the mode. In Figure 11.5, it can be seen that the sampling distributions of the mean is narrower than that of the median and the mode. In other words, it has a smaller standard error.
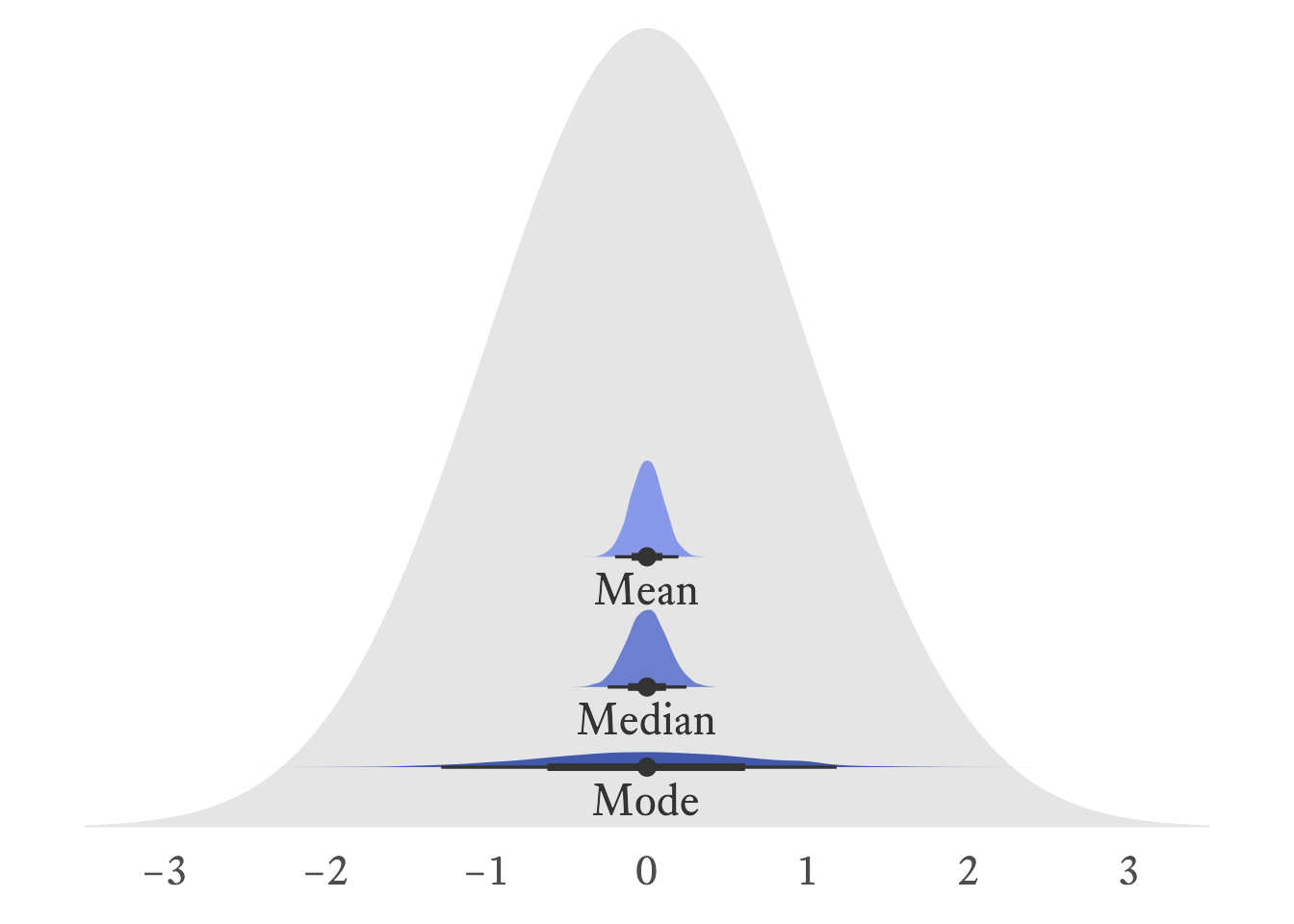
The standard normal distribution, \mathcal{N}(0,1), was used to generate 10,000 samples with a sample size of 100. The distribution of sample means is slightly narrower than the distribution of sample medians, meaning that the mean is slightly more stable than the median. The distribution of sample modes is very wide, meaning that the mode is much less stable than the mean and median.
In R, the mean function can compute the median:
Watch out for missing values in R. If the distribution has even a single missning value, the mean function will return NA, as will most other summary functions in R (e.g., median, sd, var, and cor).
To calculate the mean of all non-missing values, specify that all missing values shoule be removed prior to calculation like so:
11.2.4 Comparing Central Tendency Measures
Which measure of central tendency is best depends on what kind of variable is needed and also what purpuse it serves. Table 11.4 has a list of comparative features of each of the three major central tendency measures.
| Feature | Mode | Median | Mean |
|---|---|---|---|
| Computable for Nominal Variables | Yes | No | No |
| Computable for Ordinal Variables | Yes | Yes | No |
| Computable for Interval Variables | Yes | Yes | Yes |
| Computable for Ratio Variables | Yes | Yes | Yes |
| Algebraic Formula | No | No | Yes |
| Unique Value | No | Yes | Yes |
| Sensitive to Outliers/Skewness | No | No | Yes |
| Standard Error | Larger | Smaller | Smallest |
11.3 Expected Values
At one level, the concept of the expected value of a random variable is really simple; it is just the population mean of the variable. So why don’t we just talk about population means and be done with this “expected value” business? It just complicates things! True. In this case, however, there is value in letting some simple things appear to become complicated for a while so that later we can show that some apparently complicated things are actually simple.
Why can’t we just say that the expected value of a random variable is the population mean? You are familiar, of course, with the formula for a mean. You just add up the numbers and divide by the number of numbers n:
m_X=\frac{\sum_{i=1}^{n} {x_i}}{n}
Fine. Easy. Except…hmm…random variables generate an infinite number of numbers. Dividing by infinity is tricky. We’ll have to approach this from a different angle…
The expected value of a random variable is a weighted mean. A mean of what? Everything in the sample space. How are the sample space elements weighted? Each element in the sample space is multiplied by its probability of occurring.
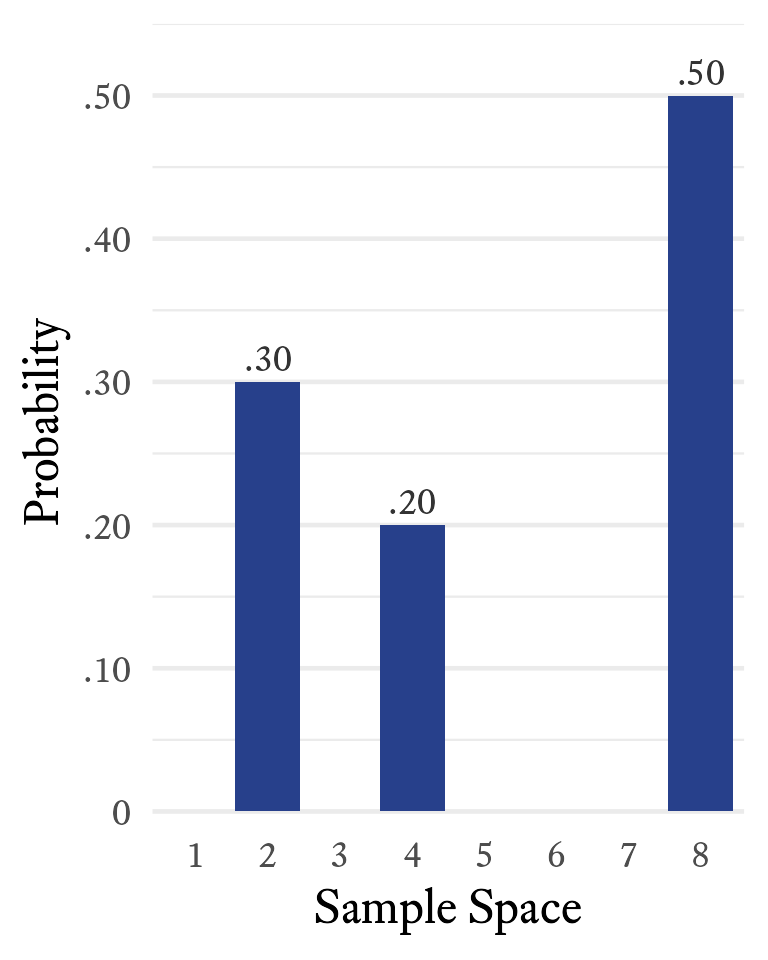
Suppose that the sample space of a random variable X is {2, 4, 8} with respective probabilities of {0.3, 0.2, 0.5}, as shown in Figure 11.6.
The notation for taking the expected value of a random variable X is \mathcal{E}(X). Can we find the mean of this variable X even if we do not have any samples it generates? Yes. To calculate the expected value of X, multiply each sample space element by its associated probability and then take the sum of all resulting products. Thus,
\begin{align*} \mathcal{E}(X)&=\sum_{i=1}^{3}{p_i x_i}\\ &= p_1x_1+p_2x_2+p_3x_3\\ &= (.3\times 2)+(.2\times 4)+(.5\times 8)\\ &=5.4 \end{align*}
The term expected value might be a little confusing. In this case, 5.4 is the expected value of X but X never once generates a value of 5.4. So the expected value is not “expected” in the sense that we expect to see it often. It is expected to be close to the mean of any randomly selected sample of the variable that is sufficiently large.
\mathcal{E}(X)=\lim_{n \to \infty} \frac{1}{n}\sum_{i=1}^{n} {x_i}
If a random variable X is discrete, its expected value \mathcal{E}(X) is the sum of each member of the sample space x_i multiplied by its probability of occurring p_i. The probability of occurring is the output of X’s probability density function at that location: p_i=f_X(x_i). Thus,
\mathcal{E}(X)=\sum_{i=-\infty}^{\infty}{x_i f_X(x_i)}
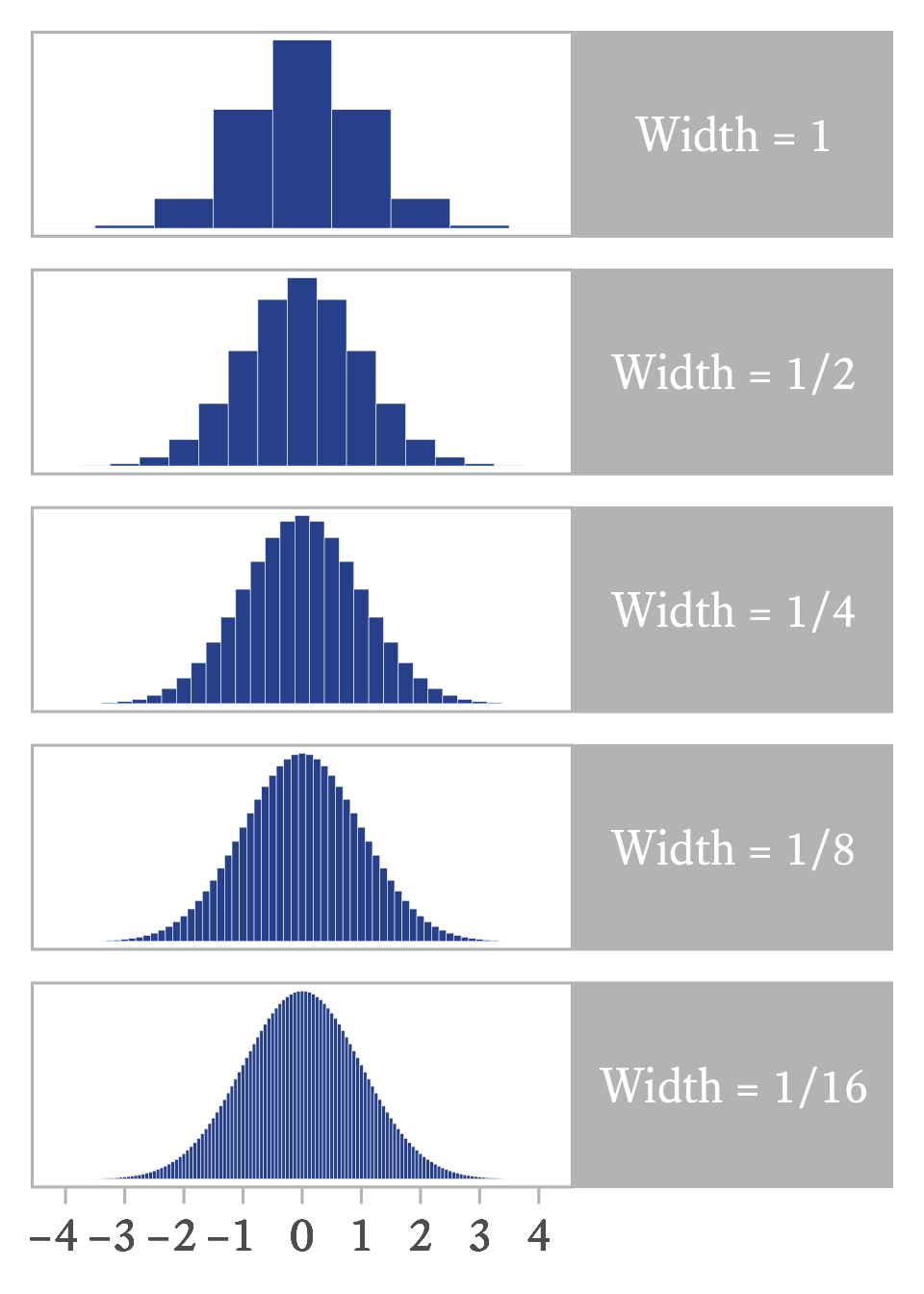
With continuous variables, the number of elements in a sample is infinite. Fortunately, calculus was designed to deal with this kind of infinity. The trick is to imagine that the continuous variable is sliced into bins and that the bins are sliced ever more thinly. If a continuous random variable has probability density function f_X(x), the expected value is
\mathcal{E}(X)=\int_{-\infty}^{\infty} {x f_X(x)\,\mathrm{d}x}
If we multiply each value of X by the height of its bin (p), we get the mean of the binned distribution. If the bins become ever thinner, as in Figure 11.7, the product of X and p approximates the expected value of the smooth continuous distribution.
11.3.1 Algebra of Expected Values
If k is a constant, its expected value is itself.
\mathcal{E}(k)=k A constant can be factored out of an expected value operator.
\mathcal{E}(kX)=k\mathcal{E}(X) The expected value of the sum of two random variables is the sum of their respective expected values:
\mathcal{E}(X+Y)=\mathcal{E}(X)+\mathcal{E}(Y)
11.4 Measures of Variability
11.4.1 Variability of Nominal Variables
For most purposes, the visual inspection of a frequency distribution table or bar plot is all that is needed to understand a nominal variable’s variability. I have never needed a statistic that measures the variability of a nominal variable, but if you need one, there are many from which to choose. For example, Wilcox (1973) presented this analog to variance for nominal variables:
\text{VA} = 1-\frac{1}{n^2}\frac{k}{k-1}\sum_{i=1}^k\left(f_i-\frac{n}{k}\right)^2
The qualvar package (Gombin, 2018) can compute the primary indices of qualitative variation presented by Wilcox.
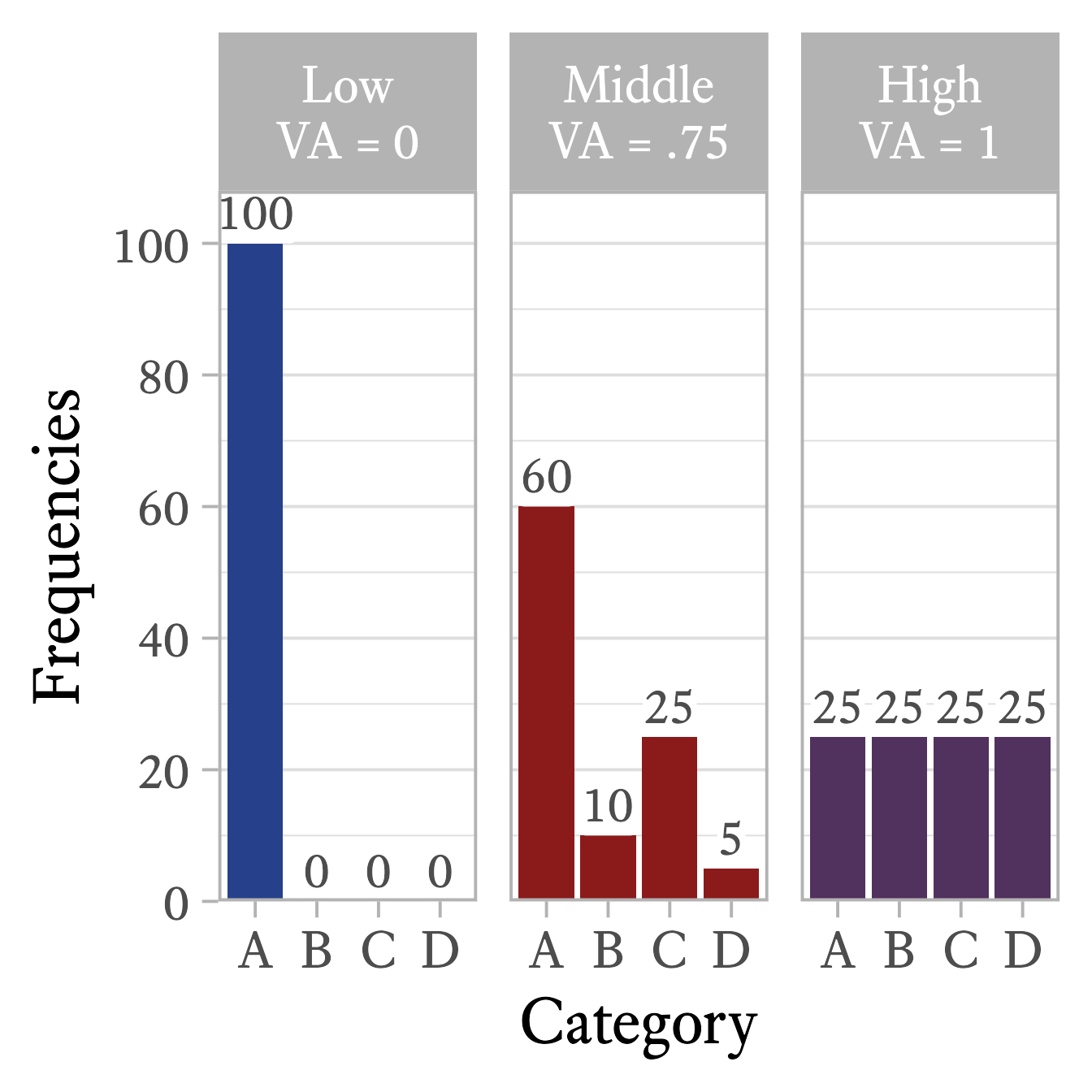
[1] 0.7533333In all of these indices of qualitative variation, the lowest value is 0 when every data point belongs to the same category (See Figure 11.8, left panel). Also, the maximum value is 1 when the data points are equally distributed across categories (See Figure 11.8, right panel).
11.4.2 Interquartile Range
As with nominal variables, a bar plot or frequency distribution table can tell you most of what you want to know about the variability of an ordinal variable. If you need a quantitative measure of how much an ordinal variable varies, you have many options. The most important of these is the interquartile range.
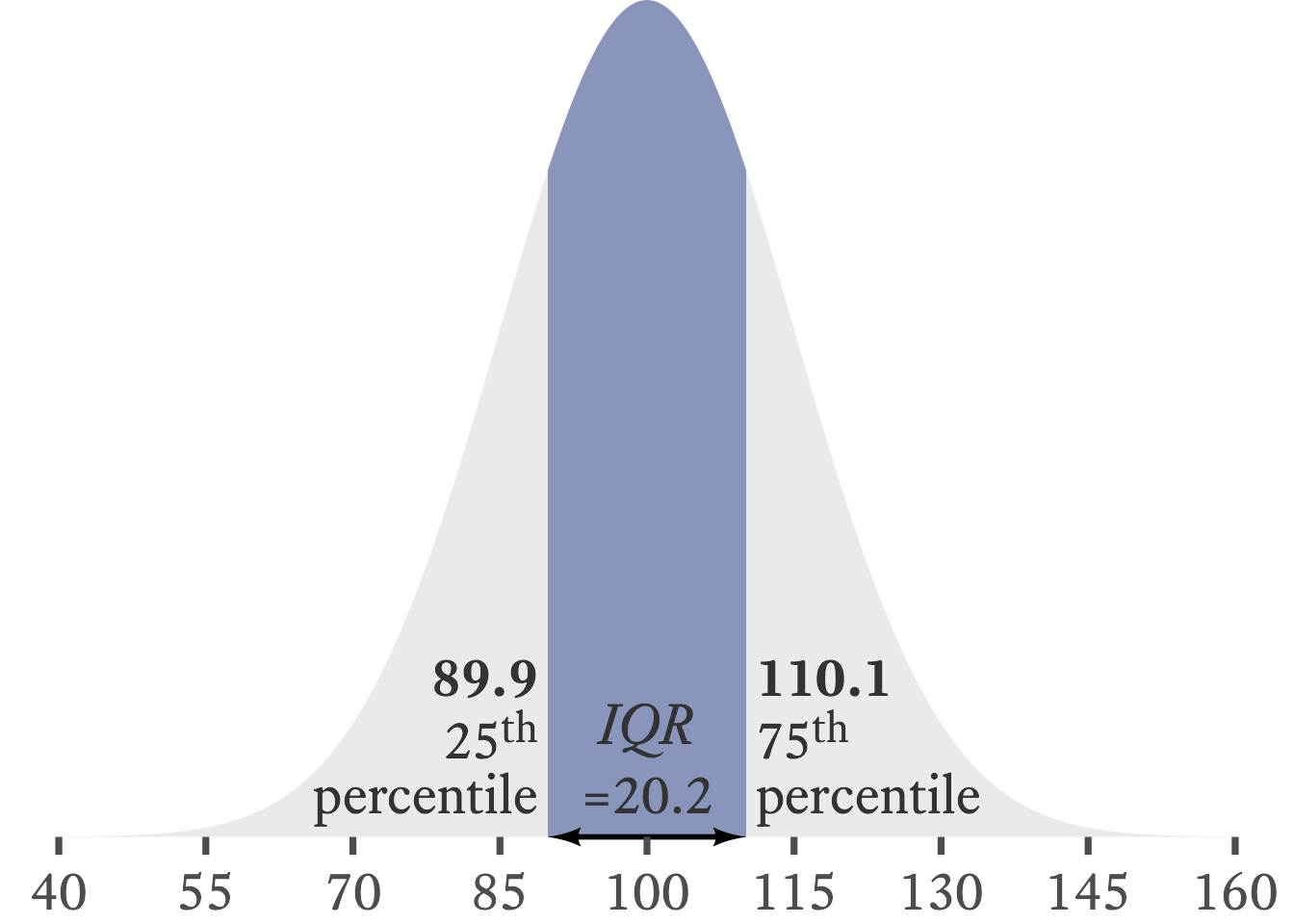
When median is a good choice for our central tendency measure, the interquartile range is usually a good choice for our variability measure. Whereas the median is the category that contains the 50th percentile in a distribution, the interquartile range is the distance between the categories that contain the 25th and 75th percentile. That is, it is the range of the 50 percent of data in the middle of the distribution. For example, in Figure 11.9, the shaded region is the space between the 25th and 75th percentiles in a normal distribution. The IQR is the width of the shaded region, about 20.2.
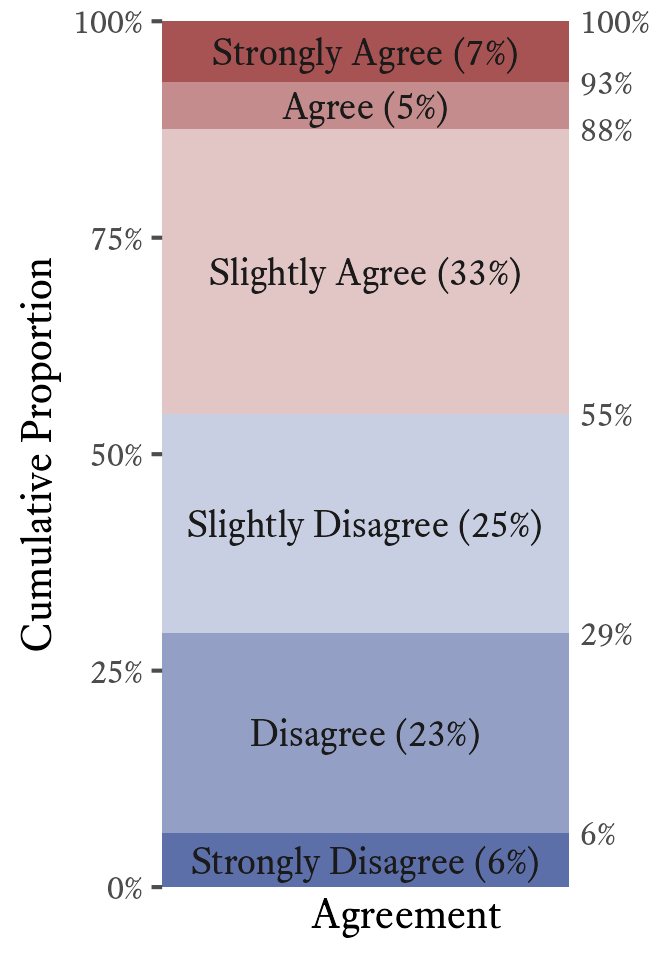
In ordinal data, there is no distance between categories, thus we cannot report the interquartile range per se. However, we can report the categories that contain the 25th and 75th percentiles. In Figure 11.10, the interquartile range has its lower bound at Disagree and its upper bound at Slightly Agree.”
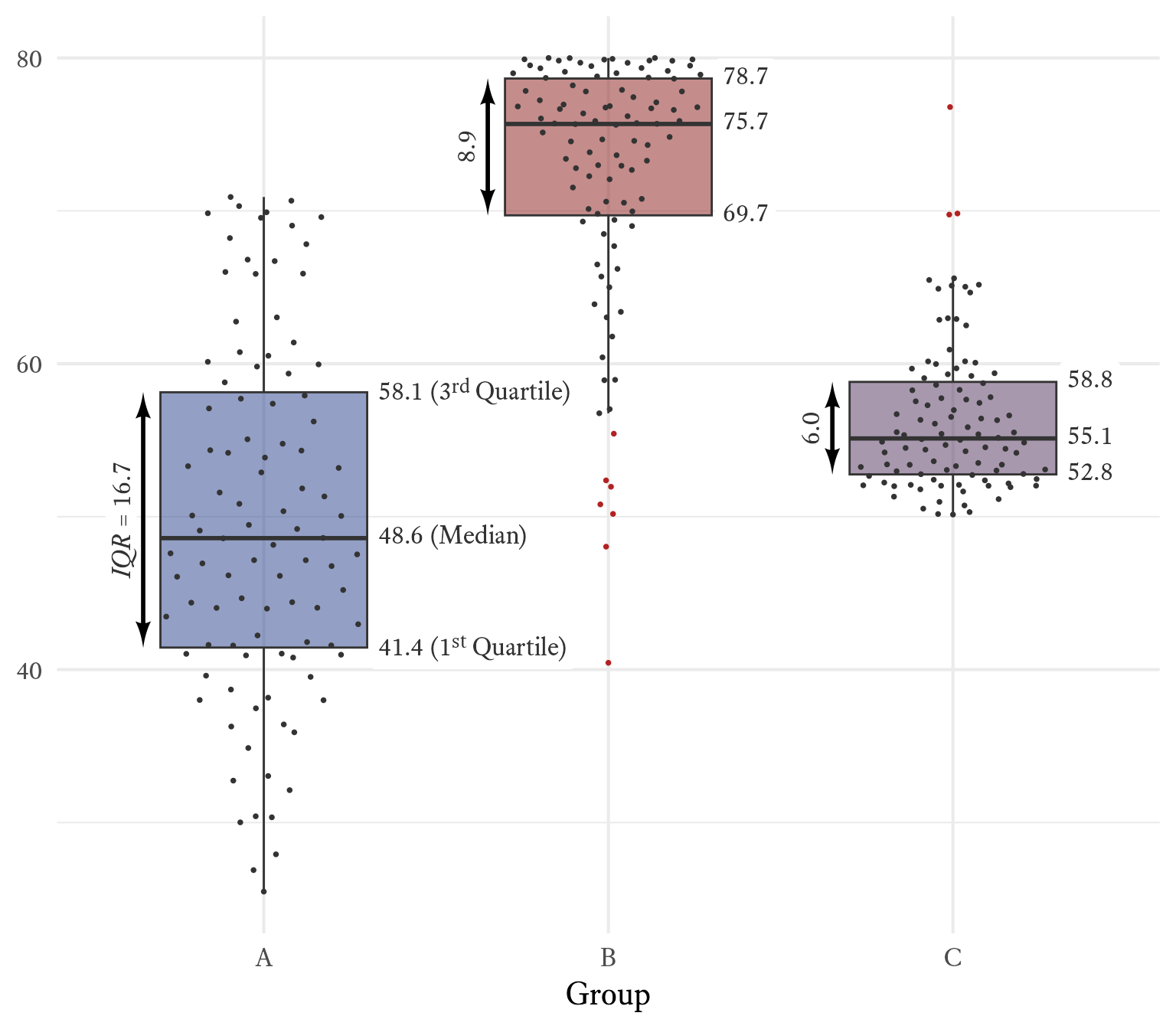
The median and the interquartile range are displayed in box and whiskers plots like Figure 11.11. The height of the box is the interquartile range, and the horizontal line is the median. The top “whisker” extends no higher than 1.5 × IQR above the 75th percentile. The bottom “whisker” extends no lower than 1.5 × IQR below the 25th percentile. Any data points outside the whiskers can be considered outliers.
11.4.3 Variance
A deviation is computed by subtracting a score from its mean:
X-\mu
We would like to know the typical size of the deviation X-\mu. To do so, it might seem intuitively correct to take the average (i.e., expected value) of the deviation, but this quantity is always 0:
\begin{aligned} \mathcal{E}(X-\mu)&=\mathcal{E}(X)-\mathcal{E}(\mu)\\ &=\mu-\mu\\ &=0 \end{aligned}
Because the average deviation is always 0, it has no utility as a measure of variability. It would be reasonable to take the average absolute value of the deviations, but absolute values often cause algebraic difficulties later when we want to use them to derive other statistics. A more mathematically tractable solution is to make each deviation positive by squaring them.
Variance \left(\sigma^2\right) is the expected value of squared deviations from the mean \left(\mu\right):
\sigma^2=\mathcal{E}\!\left(\left(X-\mu\right)^2\right) \tag{11.1}
If all elements of a population with mean \mu are known, the population variance is calculated like so:
\sigma^2=\frac{\sum_i^n{\left(x_i-\mu\right)^2}}{n}
Notice that the population variance’s calculation requires knowing the precise value of the population mean. Most of the time, we need to estimate the population mean \mu using a sample mean m. A sample variance \left(s^2\right) for a sample size n can be calculated like so:
s^2=\frac{\sum_i^n{\left(x_i-m\right)^2}}{n-1}
.jpg)
Image Credits
.jpg){kind=link}
Unlike with the population variance, we do not divide by the sample size n to calculate the sample variance. If we divided by n, the sample variance would be negatively biased (i.e., it is likely to underestimate the population variance). In what is known as Bessel’s correction (i.e, dividing by n-1 instead of by n), we get an unbiased estimate of the variance.
Variance is rarely used for descriptive purposes because it is a squared quantity with no direct connection to the width of the distribution it describes. We mainly use variance as a stepping stone to compute other descriptive statistics (e.g., standard deviations and correlation coefficients) and as an essential ingredient in inferential statistics (e.g., analysis of variance, multiple regression, and structural equation modeling). However, Figure 11.13 attempts a visualization of what variance represents. Along the X-axis, the values of a normally distributed variable X are plotted as points. The Y-axis represents the deviations of variable X from \mu, the mean of X. For each value of X, we can create a square with sides as long as the deviations from \mu. The red squares have a positive deviation and the blue squares have a negative deviation. The darkness of the color represents the magnitude of the deviation. The black square has an area equal to the average area of all the squares. Its sides have a length equal to the standard deviation, the square root of variance.
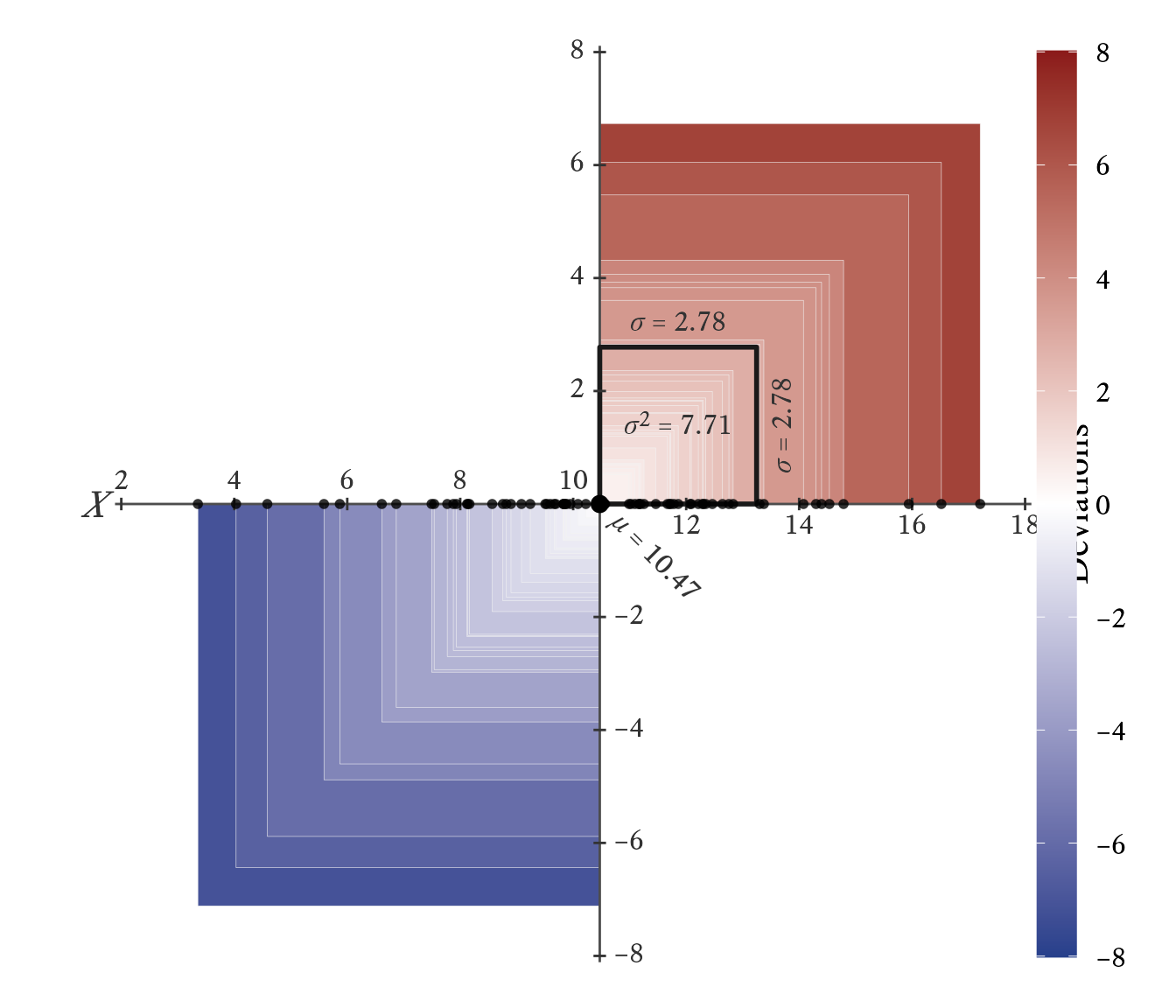
The values of variable X are plotted with the deviations of X. Each square is a deviation from the mean of X. Darker squares have larger deviations. The area of the thick black square is the variance—the average size of the squared deviations.
11.4.4 Standard Deviation
The standard deviation is by far the most common measure of variability. The standard deviation \sigma is the square root of the variance \sigma^2.
\begin{aligned} \sigma&=\sqrt{\sigma^2}=\sqrt{\frac{\sum_i^n{\left(x_i-\mu\right)^2}}{n}}\\ s&=\sqrt{s^2}=\sqrt{\frac{\sum_i^n{\left(x_i-m\right)^2}}{n-1}} \end{aligned}
Although it is not an arithmetic average of the deviations, it can be thought of as representing the typical size of the deviations. Technically, it is the square root of the average squared deviation.
In a normal distribution, the standard deviation is the distance from the mean to the two inflection points in the probability density curve (see Figure 11.14).
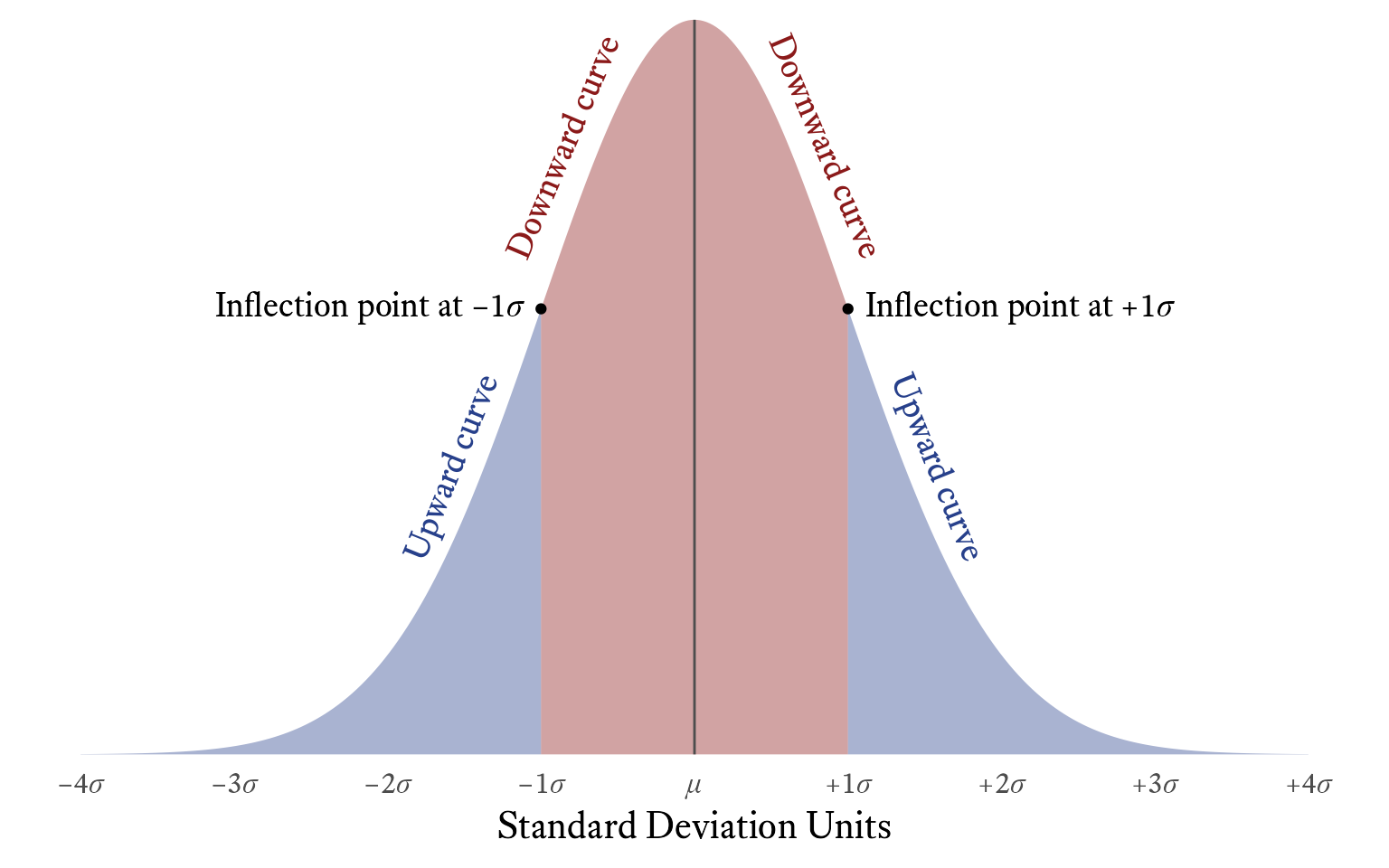
11.4.5 Average Absolute Deviations
Average absolute deviations summarize the absolution values of deviations from a central tendency measure. There are many kinds of average absolute deviations, depending which central tendency each value deviates from and then which measure of central tendency summarizes the absolute deviations. With three central tendency measures, we can imagine nine different “average” absolute deviations:
\text{The}~\begin{bmatrix}mean\\ median\\ modal\end{bmatrix}~\text{absolute deviation around the}~\begin{bmatrix}mean\\ median\\ mode\end{bmatrix}.
That said, two of these average absolute values are used more than the others: the median deviation around the median and mean deviation around the mean. One struggles to imagine what uses one might have for the others (e.g, the modal absolute deviation around the median or the mean absolute deviation around the mode).
11.4.5.1 Median Absolute Deviation (around the Median)
Suppose that we have a random variable X, which has a median of \tilde{X}. The median absolute deviation (MAD) is the median of the absolute values of the deviations from the median:
\text{Median Absolute Deviation (around the Median)}=\mathrm{median}\left(\left|X-\tilde{X}\right|\right)
A primary advantage of the MAD over the standard deviation is that it is robust to the presence of outliers. For symmetric distributions, the MAD is half the distance of the interquartile range.
11.4.5.2 Mean Absolute Deviation (around the Mean)
If the mean of random variable X is \mu_X, then:
\text{Mean Absolute Deviation (around the Mean)}=\mathcal{E}\left(\left|X-\mu_X\right|\right)
For normal distributions, the mean absolute deviation around the mean is smaller than the standard deviation by a factor of \sqrt{2\pi^{-1}}\approx 0.7979 (Geary, 1935).
The primary advantage of this statistic is that it is easy to explain to people with no statistical training. In a straightforward manner, it tells us how far each score is from the mean, on average. All else equal, when statisticians need to ensure that values are positive, they prefer to square values (as with variance) instead of taking absolute values. The absolute value often makes equations harder to manipulate algebraically and differentiate with calculus.
11.5 Skewness
(Unfinished)
Skewness refers to how lopsided the a distribution is. Skewness can range from negative to positive infinity. When a distribution has more extreme values on the upper end of its distribution (i.e., has a long right tail), it is positively skewed. When a distribution has more extreme values on the lower end of its distribution (i.e., has a long left tail), it is negatively skewed. A perfectly symmetrical distribution has a skewness of 0.
11.6 Kurtosis
(Unfinished)
12 Moments, Cumulants, and Descriptive Statistics
We can define random variables in terms of their probability mass/density functions. We can also define them in terms of their moments and cumulants.
12.1 Raw Moments
The first raw moment \mu'_1 of a random variable X is its expected value:
\mu'_1=\mathcal{E}(X)=\mu_X
The second raw moment \mu'_2 is the expected value of X^2:
\mu'_2=\mathcal{E}(X^2)
The nth raw moment \mu'_n is the expected value of X^n:
\mu'_n=\mathcal{E}(X^n)
12.2 Central Moments
The first raw moment, the mean, has obvious significance and is easy to understand. The remaining raw moments do not lend themselves to easy interpretation. We would like to understand the higher moments after accounting for the lower moments. For this reason, we can discuss central moments, which are like raw moments after subtracting mean.
One can evaluate a moment “about” a constant c like so:1
1 Alternately, we can say that this is the nth moment referred to c.
\text{The }n\text{th moment of }X\text{ about }c=\mathcal{E}\left(\left(X-c\right)^n\right)
A central moment \mu_n is a moment about the mean (i.e., the first raw moment):
\mu_n=\mathcal{E}\left(\left(X-\mu_X\right)^n\right)
The first central moment \mu_1 is not very interesting, because it always equals 0:
\begin{aligned}\mu_1&=\mathcal{E}\left(\left(X-\mu_X\right)^1\right)\\ &=\mathcal{E}\left(\left(X-\mu_X\right)\right)\\ &=\mathcal{E}\left(X\right)-\mathcal{E}\left(\mu_X\right)\\ &=\mu_X-\mu_X\\ &=0 \end{aligned}
Of note, the second central moment \mu_2 is the variance:
\mu_2=\mathcal{E}\left(\left(X-\mu_X\right)^2\right)=\sigma_X^2
12.3 Standardized Moments
A standardized moment2 is the raw moment of a variable after it has been “standardized” (i.e., converted to a z-score):
2 Standardized moments are also called normalized central moments.
Standardizing a variable by converting it to z-score is accomplished like so: z=\frac{X-\mu_X}{\sigma_X}
\text{The }n\text{th standardized moment} = \mathcal{E}\left(\left(\frac{X-\mu_X}{\sigma_X}\right)^n\right)=\frac{\mu_n}{\sigma^n}
The first two standardized moments have little use because they are always the same for every variable. The first standardized moment is the expected value of a z-score, which is always 0.
\mathcal{E}\left(\left(\frac{X-\mu_X}{\sigma_X}\right)^1\right)=\mathcal{E}\left(\frac{X}{\sigma_X}\right)-\mathcal{E}\left(\frac{\mu_X}{\sigma_X}\right)=\frac{\mu_X}{\sigma_X}-\frac{\mu_X}{\sigma_X} = 0 The second standardized moment is the expected value of a z-score squared, which is always 1.
\mathcal{E}\left(\left(\frac{X-\mu_X}{\sigma_X}\right)^2\right)=\frac{\mathcal{E}\left(\left(X-\mu_X\right)^2\right)}{\sigma_X^2} =\frac{\sigma_X^2}{\sigma_X^2}= 1
The third standardized moment is the expected value of a z-score cubed, which is one of several ways to define skewness.
The idea that skewness is the third standardized moment (i.e., the expected value of the z-score cubed) allows for an interesting interpretation of skewness. To begin, the z-score by itself is a measure of the overall level of the score. The z-score squared is a measure of variability. Thus, skewness can be seen as the relationship between deviation and variability.
\text{Skewness}=\mathcal{E}\left(z^3\right) = \mathcal{E}\left(\underbrace{z}_{\text{Level}}\cdot \underbrace{z^2}_{\text{Variability}}\right)
Thus a positively skewed variable can be described having a tendency to be become more variable (more sparse) as its value increases.
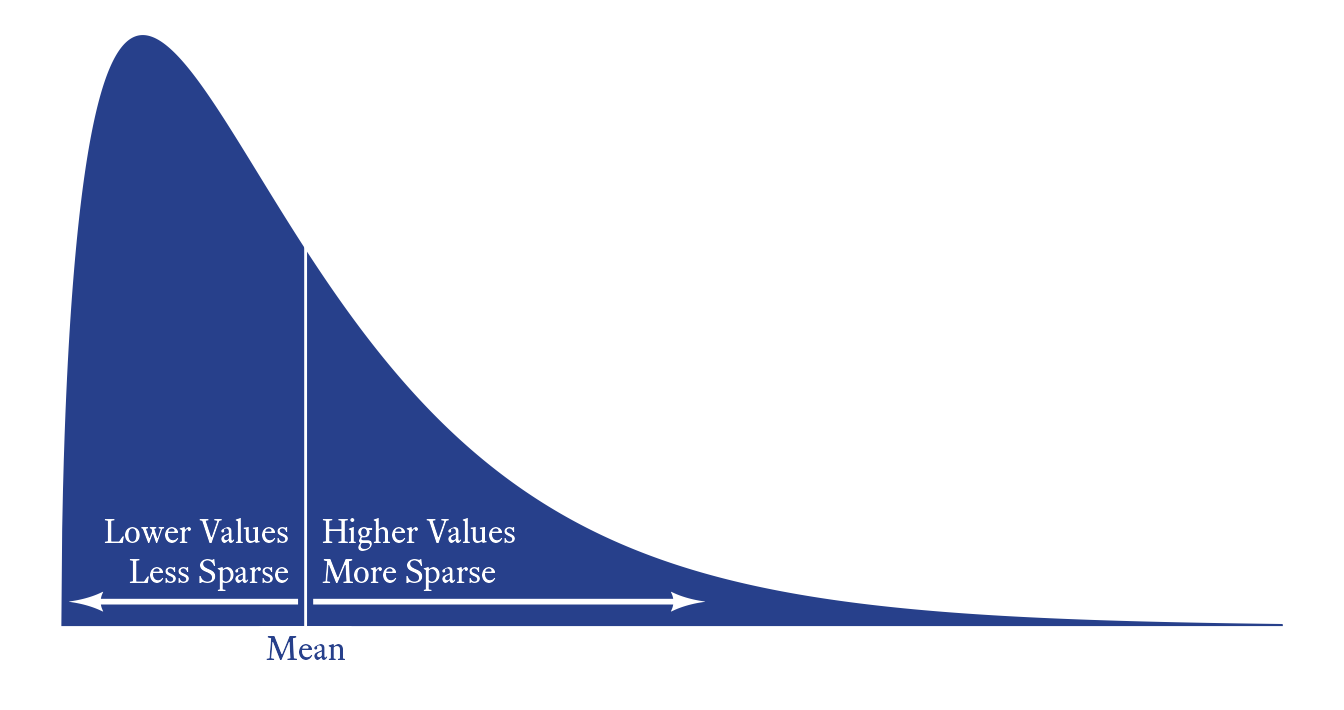
The fourth standardized moment is the expected value of the z-score raised to the fourth power. Conceptually this quantity represents the relationship between the extremity of the score and the variability of the score. When the fourth standardized moment is large, it means that scores become more variable as they become extreme at both ends of the distribution. That is, both tails of the distribution are thick, meaning that when there are outliers, they will be more extreme. When the fourth standardized moment is small, it means that scores become less variable at the extremes. In this case, the tails of the distribution will be thin such that outliers will be less extreme.
\mathcal{E}\left(\left(\frac{X-\mu}{\sigma}\right)^4\right)=\mathcal{E}\left(z^4\right)=\mathcal{E}\left(\underbrace{z^2}_{\text{Extremity}}\cdot \underbrace{z^2}_{\text{Variability}}\right)
The kurtosis statistic is the fourth standardized moment minus three. Like the fourth standardized moment, it is a measure of the thickness of a distributions tails.
\text{Kurtosis}=\mathcal{E}\left(\left(\frac{X-\mu}{\sigma}\right)^4\right)-3
Because the normal distribution has a fourth standardized moment of 3, its kurtosis is 0. Thus, kurtosis can be seen as a measure of how thick the tails of the distribution are compared to the tail thickness of the normal distribution. Kurtosis has no upper bound, but it does have a lower bound. The Bernoulli distribution with probability of .5 is either 0 or 1 with equal probability. This distribution has, essentially, no tails at all. The variability at its extremes is none whatsoever. The kurtosis of this distribution is −2, which is the lowest possible value this statistic can take.