7 Variable Scale Types
Because there are so many different kinds of variables, it is helpful to classify them by type so that we can think clearly about them and not use them incorrectly. Some statistics only make sense with certain types of variables. To take a famously silly example from Zacharias (1975), you could calculate the average number in a telephone directory, but there is no purpose in calling it. The mean has no meaning for this kind of variable. Unfortunately, it is not always so obvious which statistics can be applied to which variables. If we unknowingly apply the wrong kind of statistic to a variable, our statistical software will give us a result, but we will not know that it is nonsense.
The classic taxonomy for variable types (Stevens, 1946) distinguishes among nominal, ordinal, interval, and ratio scales (Figure 7.1). Although it is clear that this taxonomy is incomplete (Cicchetti et al., 2006), there is no consensus about how exactly the list should be amended. If this book were about how to design psychological tests, we would explore this topic in depth. For our purposes, it is enough to say that the fundamentals of measurement and scaling for variable types is philosophically complex and that controversies abound (Michell, 1997).

7.1 Nominal Scales
In a nominal scale, we note only that some things are different from others and that they belong to two or more mutually exclusive categories. If we say that a person has Down syndrome (trisomy 21), we are implicitly using a nominal scale in which there are people with Down syndrome and people without Down syndrome (as in Figure 7.2). In a true nominal scale, there are no cases that fall between categories. To be sure, we might have some difficulty figuring out and reliably agreeing upon the category to which something belongs—but there is no conceptual space between categories.

In the messy world of observable reality, few true nominal variables exist as defined here. Most so-called nominal variables in psychology are merely nominal-ish. With respect to Down syndrome, we could say that people either have three copies of the 21st chromosome or they do not. However, if we did say that—and meant it—we’d be wrong. In point of fact, there are many cases of partial trisomy (where the third chromosome is incomplete). There are other cases where there is no third chromosome, but Down syndrome is nevertheless present because parts of chromosome 21 are copied to another chromosome. However, because cases like this are sufficiently rare and because such distinctions are usually not of vital importance, Down Syndrome is treated as if it were a true nominal variable. Even though Down Syndrome might technically come in degrees (both phenotypically and in terms of the underlying chromosomal abnormalities), the distinction between having the condition and not having it is not arbitrary.
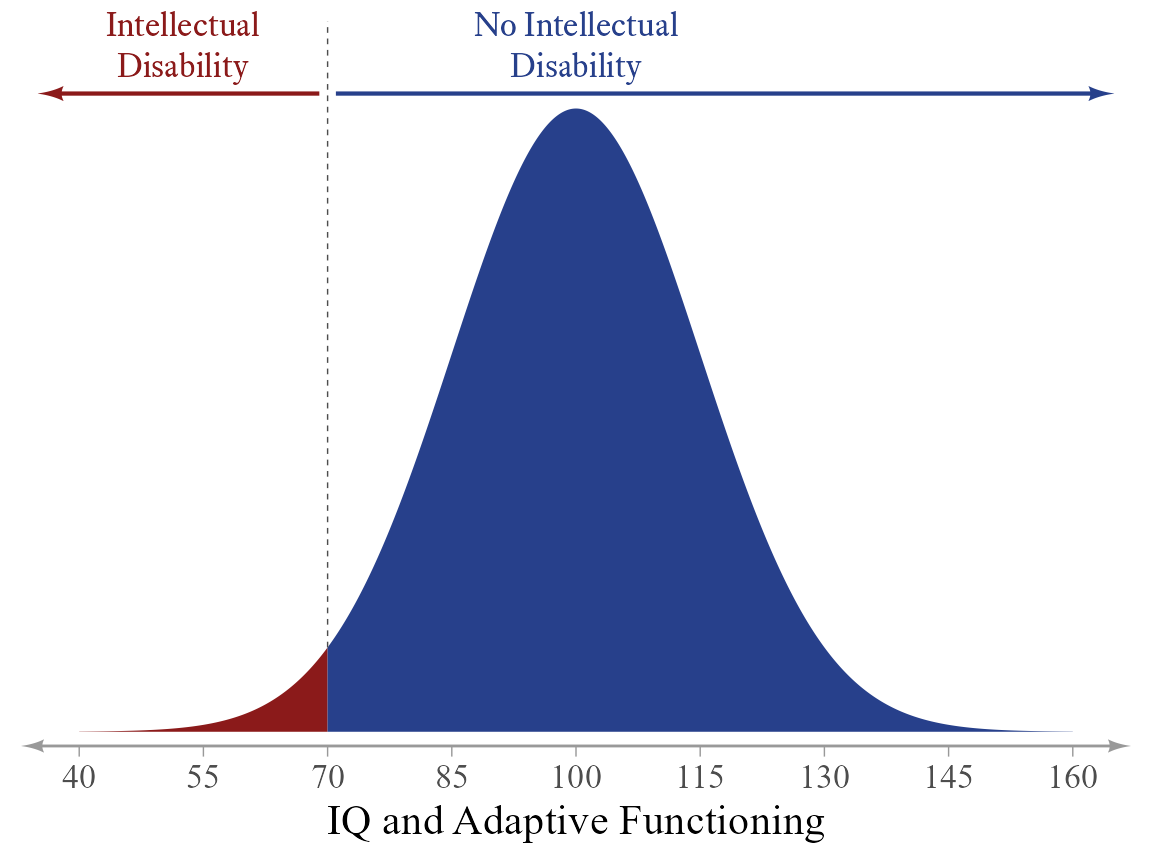
By contrast, consider the diagnosis of intellectual disability. We might have only two categories in our coding scheme (Intellectual Disability: Yes or No), but it is widely recognized that the condition comes in degrees—borderline, mild, moderate, severe, and profound (American Psychiatric Association, 2022). Thus, intellectual disability is not even conceptually nominal. It is a continuum that has been divided at a convenient but mostly arbitrary point (Figure 7.3). Distinguishing between a dichotomous variable that is nominal by nature and one that has an underlying continuum matters because there are statistics that apply only to the latter type of variable, such as the tetrachoric correlation coefficient (Pearson & Heron, 1913). Even so, in many procedures, the two types of dichotomies can be treated identically (e.g., comparing the means of two groups with an independent-samples t-test).
What if the categories in a nominal scale are not mutually exclusive? For example, suppose that we have a variable in which people can be classified as having either Down syndrome or Klinefelter syndrome (a condition in which a person has two X chromosomes and one Y chromosome). Obviously, this is a false dichotomy. Most people have neither condition. Thus, we need to expand the nominal variable to have three categories: Down syndrome, Klinefelter syndrome, and neither. What if a person has both Down syndrome and Klinefelter syndrome? Okay, we just add a fourth category: both. This combinatorial approach is not so much a problem for some purposes (e.g., the ABO blood group system), but for many variables, it quickly becomes unwieldy. If we wanted to describe all chromosomal abnormalities with a single nominal variable, the number of combinations increases exponentially with each new category added. This might be okay if having two or more chromosomal abnormalities is very rare. If, however, the categories are not mutually exclusive and combinations are common enough to matter, it is generally easiest to make the variable into two or more nominal variables (Down syndrome: Yes or No; Klinefelter syndrome: Yes or No; Edwards syndrome: Yes or No; and so forth). Some false dichotomies are so commonly used that people know what you mean, even though they are incomplete (e.g., Democrat vs. Republican) or insensitive to people who do not fit neatly into any of the typical categories (e.g., male vs. female).
When we list the categories of a nominal variable, the order in which we do so is mostly arbitrary. In the variable college major, no major intrinsically comes before any other. It is convenient to list the categories alphabetically, but the order will change as the names of college majors evolve and will differ from language to language. However, strict alphabetical order is not always logical or convenient. For example, in a variable such as ethnic identity, the number of possible categories is very large, and members of very small groups are given the option of writing in their answer next to the word “other.” To avoid confusion, the other category is placed at the end of the list rather than its alphabetical position.
7.2 Ordinal Scales
In an ordinal scale, things are still classified by category, but the categories have a particular order. Suppose that we are conducting behavioral observations of a child in school and we record when the behavior occurred. The precise time at which the behavior occurred (e.g., 10:38 AM) may be uninformative. If the class keeps a fairly regular schedule, it might be more helpful to divide the day into categories such as early morning, recess, late morning, lunch, and afternoon. This way it is easy to see if behavior problems are more likely to occur in some parts of the daily schedule than in others. It does not matter that these divisions are of unequal lengths or that they do not occur at precisely the same time each day. In a true ordinal variable, the distance between categories is either undefined, unspecified, or irrelevant.

Most measurement in psychological assessment involves ordinal scales, though in many cases ordinal scales might appear to be other types of scales. Questionnaires that use Likert scales are clearly ordinal (e.g., Figure 7.4). Even though true/false items on questionnaires might seem like nominal scales, they are usually ordinal because the answer indicates whether a person has either more or less of an attribute. That is, more and less are inherently ordinal concepts. Likewise, ability test items are ordinal, even though correct vs. incorrect might seem like nominal categories. Ability tests are designed such that a correct response indicates more ability than an incorrect response. The ordinal nature of ability test items is especially clear in cases that allow for partial credit.
Some scales are only partially ordinal. For example, educational attainment is ordinal up to a certain point in most societies, but branches out as people acquire specialized training. For a career in psychology, the educational sequence is high school diploma, associate’s degree, bachelor’s degree, master’s degree, and doctoral degree.1 However, this is not the sequence for real estate agents, hair stylists, and pilots. If we wanted to compare educational degrees across professions, how would we rank them? For example, how would we compare a law degree with a doctorate in geology? Does one degree indicate higher educational attainment than the other? The answers depend on the criteria that we care about—and different people care about different things. Thus, it is difficult to say that we have an ordinal scale when we compare educational attainment across professions.
1 Obviously, some of these degrees can be skipped, and the endpoint is different for different careers in psychology. Furthermore, not all degrees related to psychology fit neatly in this sequence (e.g., the school psychology specialist degree).
2 Although paranoia is not traditionally considered a type of anxiety, it is clear that anxiety (about the possibly malevolent intentions of others) is a core feature of the trait.
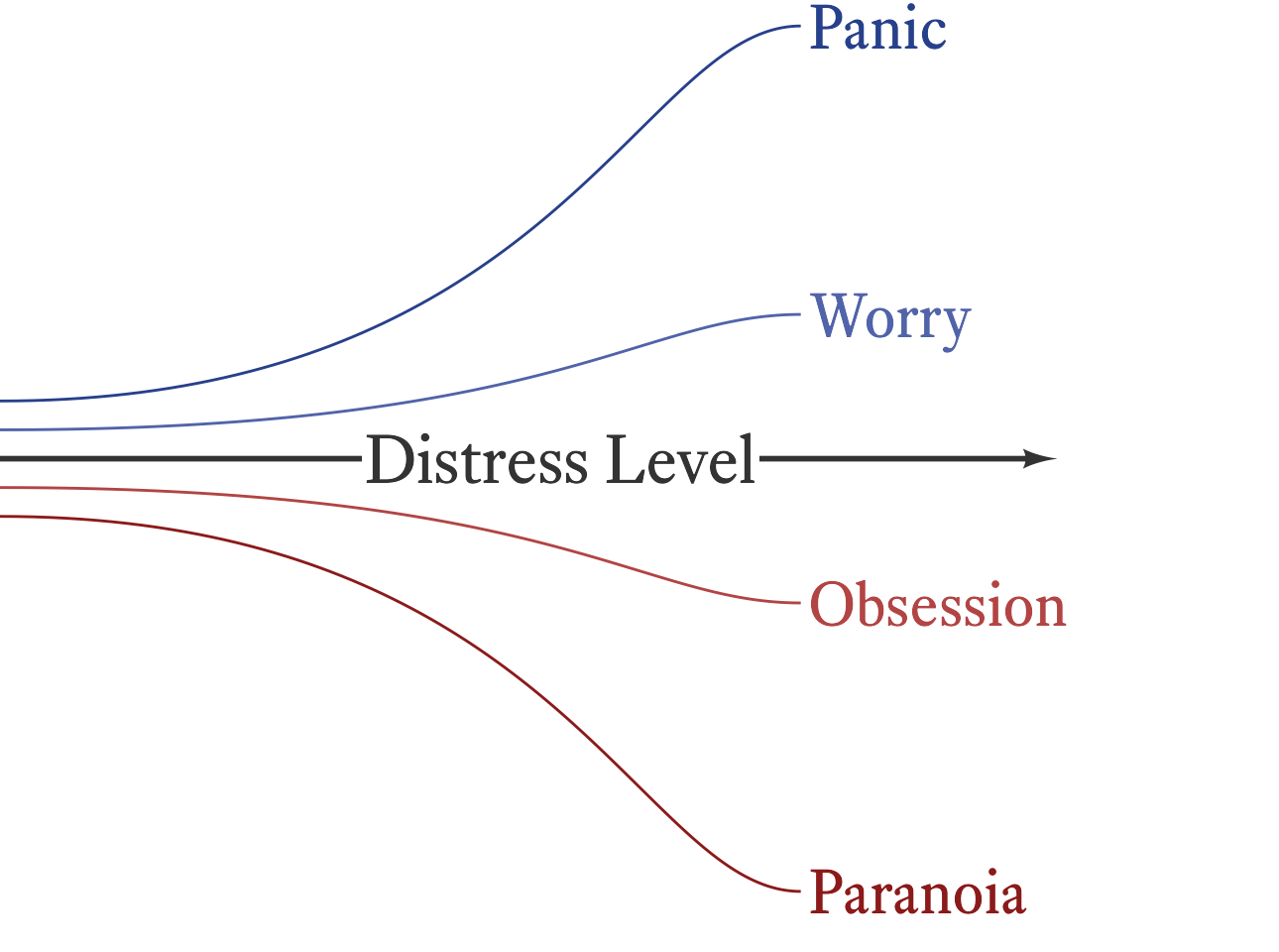
Like educational attainment, many psychological traits are more differentiated at some points in the continuum than at others. For example, as seen in Figure 7.5, it sometimes convenient to lump the various flavors of trait anxiety together at the low and middle range of distress and then to distinguish among them at the high end. It is difficult to say who is more anxious, a person who is extremely paranoid 2 or a person with a severe case of panic disorder. We can say that each is more anxious than the average person (an ordinal comparison) but each has a qualitatively different kind of anxiety. This problem is easily solved by simply talking about two different scales (paranoia and panic). However, there are different kinds of paranoia (e.g., different mixtures of hostility, fear, and psychosis) and different kinds of panic (e.g., panic vs. fear of panic). One can always divide psychological variables into ever narrower categories, making comparisons among and across related constructs problematic. At some point, we gloss over certain qualitative differences and treat them as if they were comparable, even though, strictly speaking, they are not.
7.3 Interval Scales
With interval scales, not only are the numbers on the scale ordered, the distance between the numbers (i.e., intervals) is meaningful. A good example of an interval scale is the calendar year. The time elapsed from 1960 to 1970 is the same as the time elapsed from 1970 to 1980. By contrast, consider a standard Likert scale from a questionnaire. What is the distance between disagree and agree? Is it the same as the distance between agree and strongly agree? If it were, how would we know? In interval scales, all such mysteries disappear.
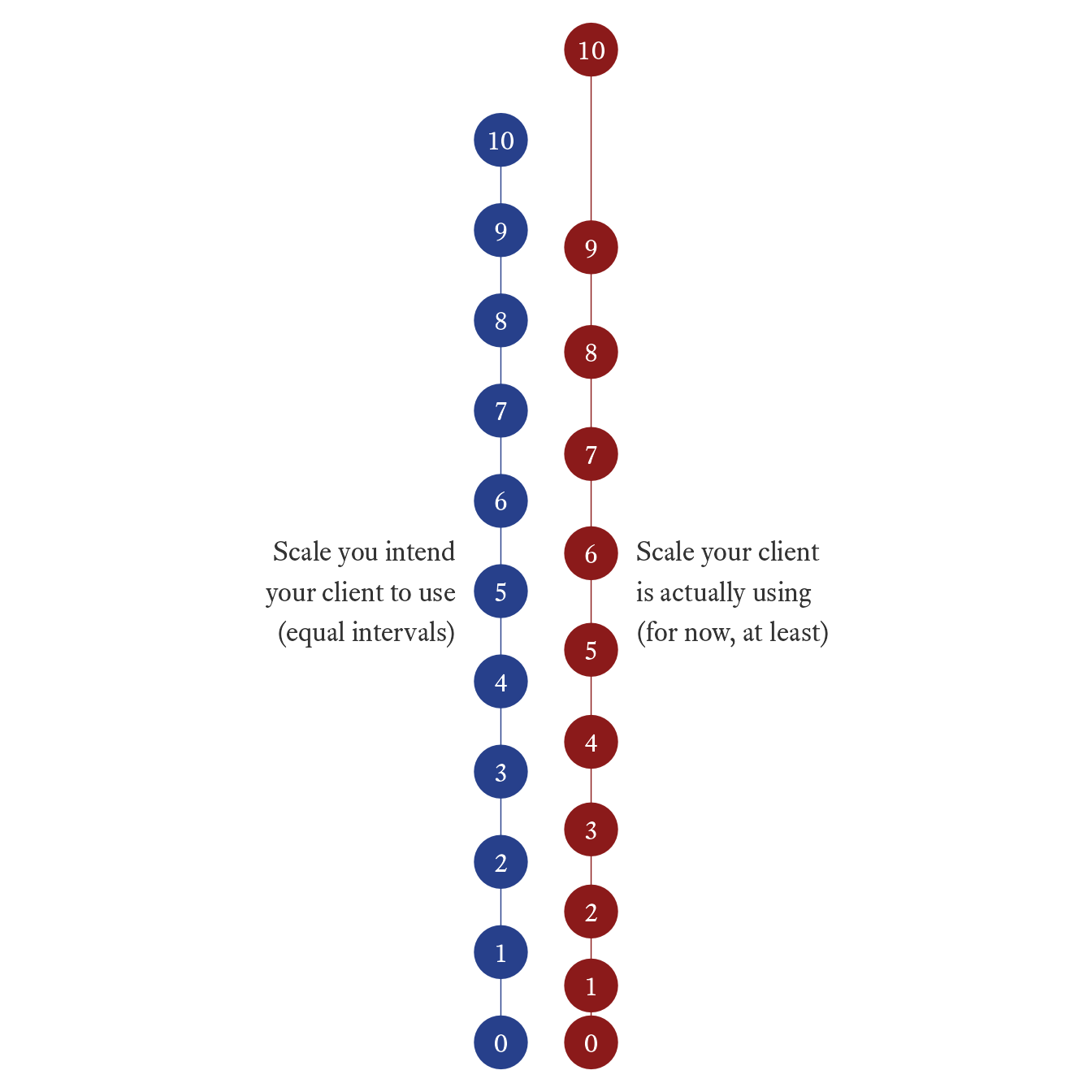
It is not always easy to distinguish between an interval scale and an ordinal scale. Therapists sometimes ask clients to rate their distress “on a scale from 0 to 10.” Probably, in the mind of the therapist, the distance between each point of the scale is equal. In the mind of the client, however, it may not work that way. In Figure 7.6, a hypothetical client thinks of the distance between 9 and 10 as much greater than the distance between 0 and 1.
It is doubtful that any subjectively scaled measurement is a true interval scale. Even so, it is clear that some ordinal scales are more interval-like than others. Using item response theory (Embretson & Reise, 2000), it is possible to sum many ordinal-level items and scale the total score such that it approximates an interval scale. It is important to note, however, that item response theory does not accomplish magic. The application of item response theory in this way is justified only if the ordinal items are measuring an underlying construct that is by nature at the interval (or ratio) level. No amount of statistical wizardry can alter the nature of the underlying construct. Sure, you can apply fancy math to the numbers, but a construct that is ordinal by nature will remain ordinal no matter what you do or convince yourself that you have done.
Most of the tools used in psychological assessment make use of ordinal scales and transform them such that they are treated as if they were interval scales. Is this defensible? Yes, a defense is possible (e.g., Michell, 2004) but not all scholars will be convinced by it (Michell, 1997, 2008). As an act of faith, I will assume that most of the scales used in psychological assessment (measures of abilities, personality traits, attitudes, interests, motivation, and so forth) are close enough to interval scales that they can be treated as such. In many instances, my faith may be misplaced, but where exactly can only be determined by high quality evidence. While I await such evidence, I try to balance my faith with moderate caution.
7.4 Ratio Scales
In a ratio scale, zero represents something special: the absence of the quantity being measured. In an interval scale, there may be a zero, but the zero is just another number in the scale. For example, 0°C happens to be the freezing point of water at sea level but it does not represent the absence of heat.3 Ratio scales do not usually have negative numbers, but there are exceptions. For example, in a checking account balance, negative numbers indicate that the account is overdrawn. Still, a checking account balance is a true ratio scale because a zero indicates that there is no money in the account.
3 The absence of heat occurs at −273.15°C or 0°K.
What does a true zero have to do with ratios? In interval scales, numbers can be added and subtracted but they cannot be sensibly divided. Why not? Because when you divide one number by another, you are creating a ratio. A ratio tells you how big one number is compared to another number. Well, how big is any number? The magnitude of a real number is its distance from zero (i.e., its absolute value). If zero is not a meaningful number on a particular scale, then ratios computed from numbers on that scale will not be meaningful. Therefore, because interval scales do not have a true zero, meaningful ratios are not possible. For example, although 20°C is twice as far from 0°C as 10°C, it does not mean that 20°C is twice as hot as 10°C. By contrast, these types of comparisons are possible on the Kelvin scale because 0°K is a true zero representing the complete absence of heat. That is, 20°K really is twice as hot as 10°K.
In psychological assessment, there are a few true ratio scales that are commonly used. Whenever anything is counted (e.g., counting how often a behavior occurs in a direct observation), it is a ratio scale. However, treating counts of behavior as ratio scales can be tricky. If I observe how many times a child speaks out of turn in class, and I use this as an index of impulsivity, it is no longer a ratio scale. Why? The actual variable, number of outbursts is a true ratio variable because 0 outbursts means the absence of outbursts. However, if I use the number of outbursts as a proxy variable for impulsivity, then 0 outbursts probably does not indicate the absence of impulsivity. At best it indicates lower levels of impulsivity. We can observed two children with 0 outbursts yet imagine that one child is still more impulsive than the other. This same problem exists for the measurement of reaction times. Reaction time is a true ratio scale because a reaction time of 0 means that no time has elapsed between the onset of the stimulus and the response. However, reaction time data used in clinical applications are often proxies for traits that are interval-level concepts, such as inattention on a continuous performance test. Why are psychological traits such as cognitive abilities, personality traits, and so forth interval-level concepts? Because we do not yet have any means of defining what, for example, zero intelligence or zero extroversion would look like. Attempts have been made (Jensen, 2006), but they have not yet proved persuasive.
7.5 Discrete vs. Continuous Variables
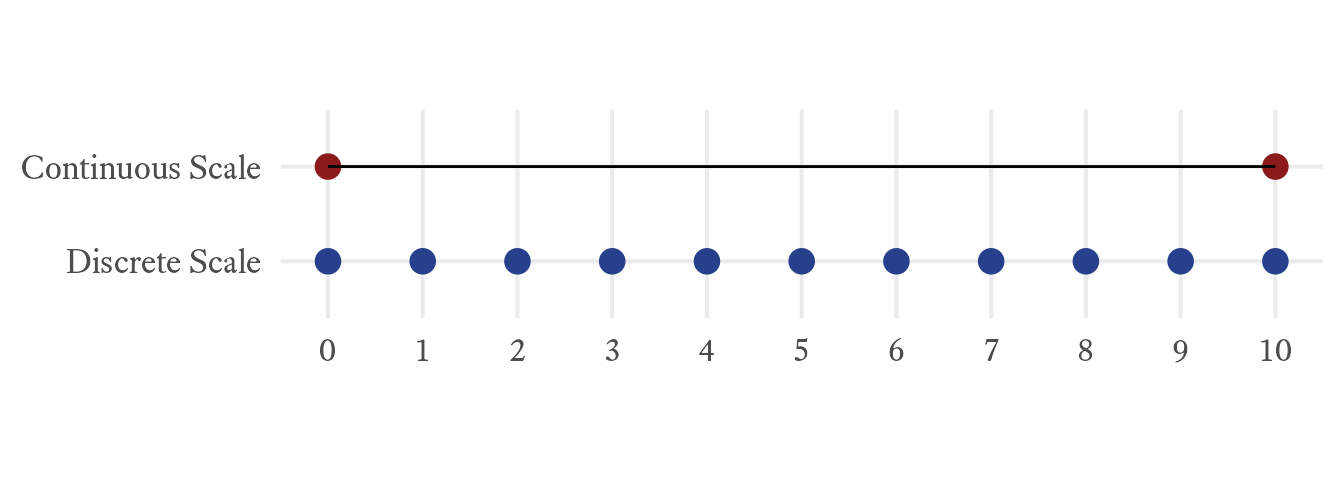
Interval and ratio variables can be either discrete or continuous. Discrete variables can assume some values but not others. Once the list of acceptable values has been specified, there are no cases that fall between those values. For example, the number of bicycles a person owns is a discrete variable because the variable can assume only the non-negative integers. Fractions of bicycles are not considered. Discrete variables often take on integer values, but any set of exact, isolated values can be used in a discrete variable. For example, one could specify a discrete variable that is divided at every half point: 0.0, 0.5, 1.0, 1.5, 2.0, 2.5, ….
When a variable can assume any value within a specified interval, the variable is said to be continuous. With a continuous variable, we can use fractions and decimals to achieve any level of precision that we desire. In Figure 7.7, blue circles present the set of integers from 0 to 10. No fractions between the integers occur in the variable. By contrast, the solid red line from 0 to 10 represents the values that can occur in a continuous variable. Any and all fractional values are possible, but in practice we must round to a feasibly useful level of precision.